Distributed Computing with Python的阅读笔记
最近要把一年以前没有完成的计划给完成掉,分布式就是其中一个,为了在一开始有个大概的了解,我决定选一本用指定编程语言并且 厚度不高的书来学习,这本Distributed Computing with Python就满足了我的需求,共154页,其中第5,6两章是关于使用AWS和 HPC来部署分布式应用,我跳过了这两章节.第2节是讲述异步编程(asynchronous/event-driven programming)的概念,这个快 速地过了一遍,第3章是关于如何使用Python来并行.第7章给了测试与调试的一些建议.第8章是最这本书来个大概总结,可以直接跳 过.重点是第4章,用了Celery,RabbitMQ和Redis来写例子示范如何编写分布式应用.当然这种关于大题材的薄书涵盖的点都不会很 全面的,但我倾向于那种能够在开始给个概念和示范的书,至于更深入的细节,以后再读相关的书,这里面所有的图片都是来自于这本 书.
概念
并行计算(Parallel computing)
同时利用多个处理器解决一个问题的叫做并行计算.
Parallel computing is the simultaneous use of more than one processor to solve a problem.
为什么需要并行计算
性能原因:把一个长时间(long-running)的计算分成多个小块并且把它们分发到不同的处理器/处理器的核心上,可以节省大量时间.
分布式计算(Distributed computing)
同时利用多台计算机解决同一个问题叫做分布式计算.
Distributed computing is the simultaneous use of more than one computer to solve a problem.
当然这个概念不是完全正确的,抽象就是这样,严格上来说,它还要求这些计算机是以一台计算机工作的形式展示给用户, 因此,要隐藏起分布式应用的分布本质.
- 为什么需要分布式运算
- 性能原因: 解决那种不能用一台计算机可以单独解决或者不能在一个合理时间那解决的大问题,分布式就拥有这种能力.
- 架构原因: 应用需要分布式系统,比如视频通话和即时聊天应用.
- 为什么需要分布式运算
并行计算和分布式计算的异同
两者最大的不同可能就是低层的内存架构(underlying memory architecture)和访问模式(access patterns)了.
- 在并行应用中,原则上,所有的部并发任务能够访问同一片内存空间,内存共享架构(shared-memory architecture).
- 在分布式应用中,各种各样的并发任务不能够普通地访问同一片内容空间.因为这些计算机能够通过网络与其它计算机交流,可以想像一下, 写一个能够把我们所有地应用统一在一个同一逻辑(unified logical, as opposed to physical)内存空间的软件(中间件/middleware). 这种类型的中间件确实存在,叫做分布式内存共享架构.
- 在现实中,使用的架构很可能是内存共享架构和分布式内存共享架构的混合.
- 每种架构都有自己的优点和缺点.内存共享架构由于在同一块内存下所以优点就是快,并且编写简单;同样这也是缺点,那就是要注意条件竞争 (race condition).分布式内存架构优点是可伸缩性高和组合成本低,并且每一台计算机的内存跟其它计算机的独立,不用担心条件竞争(也 不是绝对,分布式共享内存还是要做处理);缺点就是需要自己实现数据之间的移动并且还要担心数据局部性(data locality)的问题.
阿达姆尔定律(Amdahl's law)
该定律告诉我们硬件投入越多,性能的提升也能够获得越多.但是只存在一个点的收益(加速比)是最高的,也就是说不断投入硬件会 获得更多的性能,可是在一定程度后的性能收益就没那么高了.适用与并行,分布式和混合架构.
古斯塔夫森定律(Gustafson's law)
这个定律也是可以计算加速比的,不过算法不一样.
- I/O and CPU
同步(按序执行) 当一个任务执行它的I/O操作的时候,CPU就处于空闲状态并且等待I/O操作的完成(然后任务就重新执行接下来的计算).我们 说任务在等待I/O并且挂起了,也就是说任务阻塞(blocking)了,如果又多个任务执行的话,其它任务就要等上一个任务执行 完毕才可以执行下一个任务.
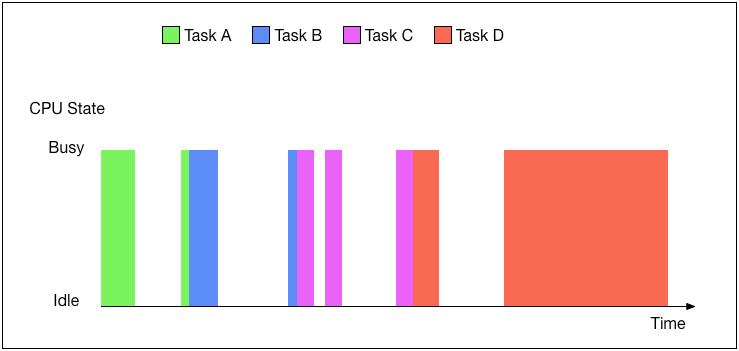
异步 跟同步任务不一样的是,任务在等待I/O的时候,CPU并没有处于空闲状态,而是被另外一个任务接管了.异步(事件驱动/非阻塞) 编程是一种编程方式,可以达到异步执行的目的.
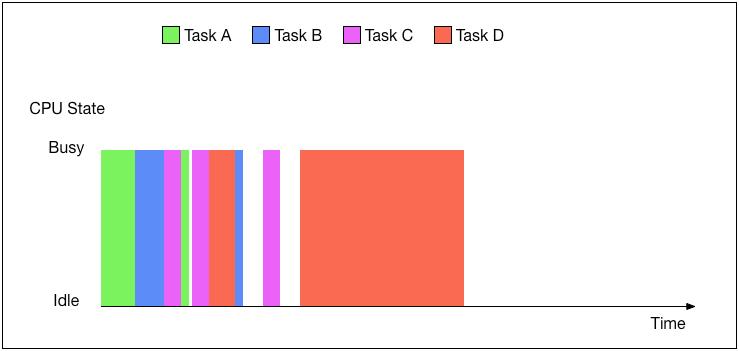
- 多线程编程 把任务并行到多个不同的线程中,拥有与异步编程一样的效率和效果.这里有一个根本上的不同:当使用一个多线程程序, 操作系统可以决定激活哪个线程和挂起哪个线程.而在异步编程中,每一个任务可以决定什么时候放弃CPU并且挂起它的 执行.
竞争条件(Race condition) 程序本应该要正确地按照给定的顺序执行,这样才不会出现同一个输入有不同结果的情况出现.在多线程编程中,这是一个要注意 的问题,对同一个资源进行访问的时候,当访问是这一系列连续操作时(非原子性)的时候,其它线程如果也刚好访问这个资源的话, 那么就会被别的线程占据资源.也就是说的竞争(Race).
这个概念常常和数据争用(Data race)搞混,两者也确实是有点相识,数据争用是说多个线程对一个变量同时进行读/写操作(只读 不算).
Global Interpreter Lock (GIL)
正如名字提示的一样,GIL是一个全局锁,它的作用是让引用计(reference counting)正常工作.Python的 多线程的确是系统级的线程(OS-native threads),不过由于GIL,Python中的线程不能想上面说的并行到 别的CPU上,因为同一时间只能有一个线程激活.这导致了Python解析器是一个单线程的解析器,这句话并不 完全对的.在标准的Python中,最好不用多线程去做CPU计算,多进程是一个选择.
如何在workers之间交换数据(多进程)
multiprocessing模块提供队列(Queues)和管道(Pipes)可以解决这个问题,如果是支持Python进程在不同 的机器上运行并且通信,可以使用BaseManager或者Manager来实现.
基于Celery实现的分布式系统
Celery是一个分布式任务队列框架,它的模式是生产者和消费者模式,用它来实现分布式的话,需要先知道组成 这个分布式系统的几个部分,
master process(client or producer)
主进程,发布任务到任务队列(task queues)和从后端(result backend)获取结果.
broker(中间人)
消息队列软件,掌管/存放任务队列(task queues)和负责给worker processes传递消息.书中用的是RabbitMQ作为broker.
worker processes(工人进程 or consumers)
接收broker传递的信息并且完成分配的任务.
result backend(结果后端)
储存worker processes的任务结果, master process会在这里取结果.书中使用了RabbitMQ和Redis其中之一作为后端.
一个典型的由Celery搭建的分布式系统的图,如下
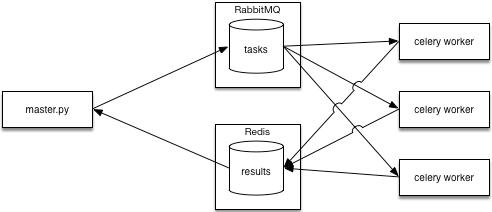
通常来讲broker和result backend会运行在同一台机器中,接下来的例子中也是这么做.
Time to show you the code
关于该项目
这只是一个小的/WEB的/示范项目,由于我手头上有一台VPS(Debian系统),我决定在它上运行broker和result backend,在 我的笔记本上运行两个workers和一个master process,然后本地访问.如果读者自己也想跟着做练习,可以自备一台VPS或者 搭虚拟机建立一个局域网.项目目录如下,
salt@salt:~/Documents/celery-web$ tree . ├── config.py ├── master.py ├── requirements.txt ├── worker1.py └── worker2.py 0 directories, 4 files
这个项目没什么功能,只是看完书后自己的一个小实践,主要是学习怎么使用Celery,书上虽然有演示项目,不过不在比较真实 的情况下练习的话,可能会接触不了以后要解决的问题.因此本人就用真的服务器来做练习.
这个项目使用的依赖(requirements.txt)为
celery==4.2.1 gevent==1.3.6 redis==2.10.6 tornado==5.1
- 部署准备
在VPS上面安装好RabbitMQ-Server和Redis-Server
apt-get install rabbitmq-server redis-server
新建一个RabbitMQ的用户,因为默认的guest用户只能用于本地访问(当然guest用户也是可以获得远程访问权限), 这一步对于远程访问是必须的
root@my-vps:~# rabbitmqctl add_user salt saltpw Creating user "salt" root@my-vps:~# rabbitmqctl set_user_tags salt administrator Setting tags for user "salt" to [administrator] ... root@my-vps:~# rabbitmqctl set_permissions -p / salt ".*" ".*" ".*" Setting permissions for user "salt" in vhost "/" ... root@my-vps:~#
这里是新建一个密码为saltpw的salt rabbitmq用户,并且给它设定一个叫administrator的tag(只是用来标识而已), 最后授与了它所有权限.
更多关于rabbitmqctl命令的使用请以下命令
rabbitmqctl -h
对于Redis,也需要配置一下,目标是开启远程访问和配置密码
在/etc/redis/redis.conf里面做出以下改动
- 把bind 127.0.0.1注释掉,bind指令用于指定可以访问到本机的Redis数据库的IP,bind 127.0.0.1已是就是 只有127.0.0.1可以访问的意思.
- 加入requirepass <yourpassword>,<yourpassword>改为你想要的密码,假设这里是saltb0rn.
- 把protected-mode yes改为protected-mode no
项目代码
# -*- coding: utf-8 -*- # !/usr/bin/env python3 # config.py BROKER_URL = 'amqp://salt:saltpw@darksalt.me' CELERY_RESULT_BACKEND = 'redis://:saltb0rn@darksalt.me' CELERY_IMPORTS = ("worker1", "worker2") # celery是需要开发人员手动导入任务模块,而且不能用相对路径, # 否则任务就会是未注册,"Received unregistered task of type 'worker1.sleep'.", # 模块在下面给出.
# -*- coding: utf-8 -*- #! /usr/bin/env python3 # master.py import datetime import tornado.gen import tornado.httpserver import tornado.ioloop import tornado.web from tornado.options import define, options from gevent import monkey from worker1 import sleep from worker2 import eat define("port", default=8000, help="run on the given port", type=int) define("debug", default=True, help="run in debug mode", type=bool) monkey.patch_all() class SleepingHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self): sleep.apply_async(args=(6,)).then(self.process_result) self.write('sleep at {}'.format(datetime.datetime.now())) def process_result(self, result): print("{}".format(result.result)) class EatingHandler(tornado.web.RequestHandler): @tornado.gen.coroutine def get(self): eat.apply_async((4,)).then(self.process_result) self.write('eat at {}'.format(datetime.datetime.now())) def process_result(self, result): print("{}".format(result.result)) if __name__ == "__main__": options.parse_command_line() app = tornado.web.Application( handlers=[ (r"/api/v1/sleep", SleepingHandler), (r"/api/v1/eat", EatingHandler), ], debug=options.debug ) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(options.port) tornado.ioloop.IOLoop.instance().start()
这里的master.py使用了celery的AsyncResult的then方法,这里根据文档上的例子用了gevent打patch, 否则then里面的回调是不会执行.
要注意的是,一个worker为一个节点(node),不同workers跑在同一台计算机上面需要设定不同的node name ,也就是hostname.否则最后启动的node会把同一台计算机上先启动的同名的nodes结束掉.
# -*- coding: utf-8 -*- # !/usr/bin/env python3 # worker1.py import argparse import time import random from celery import Celery from celery.bin import worker app = Celery() app.config_from_object('config') @app.task def sleep(second=5): time.sleep(second) return "I get a \"{}\" from dream".format(random.randint(0, 255)) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('-c', type=int, default=1, help="number of workers") args = parser.parse_args() worker = worker.worker(app=app) worker.run(hostname='worker1@%h', concurrency=args.c, loglevel='INFO') # hostname 就是 node name
# -*- coding: utf-8 -*- # !/usr/bin/env python3 # worker2.py import argparse import time from datetime import datetime from celery import Celery from celery.bin import worker app = Celery() app.config_from_object('config') @app.task def eat(second=5): time.sleep(second) return "I've had enough, {} now".format(datetime.datetime.now()) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('-c', type=int, default=1, help="number of workers") args = parser.parse_args() worker = worker.worker(app=app) worker.run(hostname='worker2@%h', concurrency=args.c, loglevel='INFO')
测试
代码已经写完了,是时候开始测试了,
在第一个终端
salt@salt:~/Documents/celery-web$ python3 worker1.py
在第二个终端
salt@salt:~/Documents/celery-web$ python3 worker2.py
在第三个终端
salt@salt:~/Documents/celery-web$ python3 master.py
不要忘记了,例子中两个worker都是在同一台机器上面的,实际上来说,一般是一台机器一个worker,因为我手头上VPS数量 有限,所以只能这么玩.
每个worker运行的时候会有这样类似的output
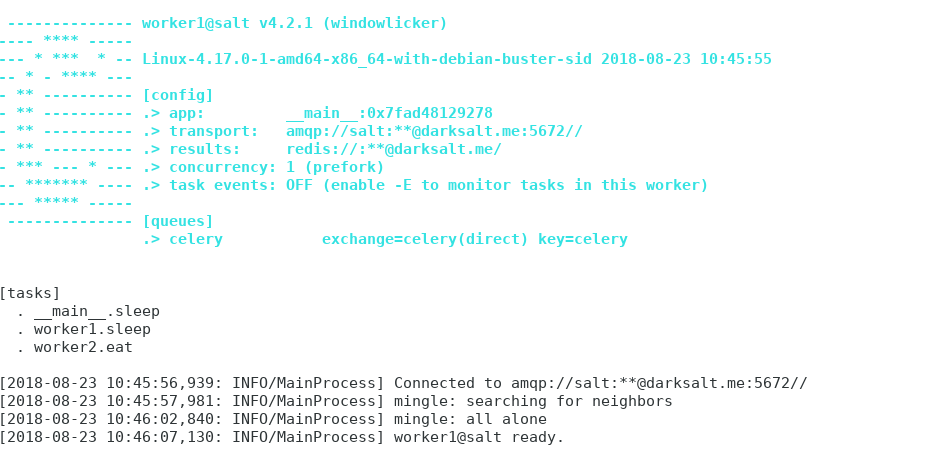
当master.py收到请求的时候,worker会显示接收了什么任务

而master.py会有如下output

这个时候就说明成功了.你可能会疑惑,为何只启动了worker1,当时tasks里面会有worker2的任务?其实这个是因为config.py 里面的'CELERYIMPORTS = ("worker1", "worker2")'设定为启动的时候两个workers的任务都导入了,其实两个workers 的任务是可以全部写到一个文件里面的,然后启动的时候设定好node name之类的就可以了,这里分成两个文件只是模拟如果对 系统的拓展,你可以想成,worker1.py是原来的功能,现在要拓展,worker2.py就是拓展的部分.
要注意,master.py处理请求的方式是异步处理,所以代码里面定义workers的任务的时候也是异步的,异步的话就不能和回调 脱离关系了.
更多的Celery的配置
关于Celery的配置,其实就是要学会如何使用Celery所涉及到brokers,result backends.不过这些都不是一两句话就可以 概括完的,所以我在之后学习一下RabbitMQ和Redis的使用并写下笔记,一共两篇笔记.
一些后话
这篇文章其实几天前就开始写了,有时间就写一下,今天终于写完了.对于分布式这个话题,其实很早之前就在我的计划表上面了,不过 发生了很多事情,今年的运气不大好,既然运气不好就更加要努力.以上只是分布式的冰山一角罢了,如果就这么一点的话,那也就称不 上一个话题了.学习之前对它有一种恐惧,学习之后感觉好像也没那么难,当然没那么难很有可能是我还没遇到困难.对新手而言,学习 的时候遇到的困难那可能就是一大堆软件了.我个人在实际操作中就发现远程连接的时候就没有书本上那么简单,也就是在部署的时候 遇到点问题,再看看Celery的配置参考时候就更加明白了学习RabbitMQ和Redis是必修课.说白了大部份时间都是花在部署上面,写代 码其实还好.
书上还说了,看完这本书的时候才刚刚开始踏入分布式的大门而已,还有更高级的话题,反正入门的目的已经达到了,高级话题以后慢慢 看.还有就是书上也推荐了Celery的两个替代品,Pyro和Python-RQ,后者没有印象,前者我倒是找RPC库的时候找到它,反正有时间再 去研究一下.