The Sllgen Parser
Table of Contents
EOPL 是一个本好书,所以我想完成上面的习题.不过主要内容只讲了如何写直译器, parser 部分只有在附录里面详细说明(可以理解,因为 parser 不是 interpreter 的一部分).
Sllgen 是 eopl 库提供的一个生成器,用来生成 lexer 和 parser.由于并没有在正文部分出现,那么我只能单独了解一下.
实现一门语言的流程/模式
EOPL 上面说过以实现一门直译语言的整个流程分两步,第一步就是 scanning 和 parsing,第二步就是 interpreting 或者 compiling.
第一步和第二步也有可以叫做前端部分和后端部分.
- 前端(front-end)
Scanning, 把源代码分为词(words),标点符号(punctuation)等等,这些单元被称为lexical items,lexmes或者最常听到的tokens(下文就用这个叫法).Parsing, 把scanning得到的tokens序列组织成一个有层次的句法结构(hierarchical syntactic structures),这种句法结构就是抽象语法树(abstract syntax tree),简称AST,下文也用这个叫法.
后端(back-end)
语言的类型运行方式有两种,直译(interpreting)和编译(compiling),也有的语言混合两种方式.
Interpreting, 运算parsing得到的AST,得出结果.负责这项工作的是interpreter,中文名叫直译器.Compiling, 把AST翻译成别的语言,这门语言可能是能够被硬件直译的机器语言(machine language),也可能是一门特定用途的直译语言,这门语言的直译器叫做虚拟机(virtual machine).负责这项工作的是
compiler,中文名叫编译器.一般Compiler可以分为两个部分,analyzer,负责推断出(deduce)程序有用的信息.translator,负责翻译/编译工作,可能会使用到analyzer得到的信息.
我们把想要实现的语言叫做 source/defined language,用于实现直译器/编译器的语言叫做 implementation/defining language,对于编译语言来说,翻译得到语言叫做 target language.
所以整个流程就是:
- 前端处理
source language的代码, - 后端处理(直译或者编译)前端得到的结果.
什么是 lexer generator, parser generator, lexer 和 parser.
Parser generator 接受 grammar 作为输入然后输出可以根据 grammar 解析字符串流的源代码.
这份源代码就是 parser,中文名解析器.实现语言流程中的前端就是 parser 的工作.
其实准确来说, parser 只是负责 parsing 的工作,还有一个 lexer, 也叫做 scanner,负责 scanning 的工作.
这个怎么划分实际上问题不大,不过推荐分开看待,知道的细节越多就证明越了解.
Lexer generator 负责根据正则表达式编写成的规则生成 lexer,一般 parser generator 都包含了它们,比如这里的 sllgen.
经常听到的 lexer generator 有 lex 和 flex.
Parser generator 有很多,比如 Java 用的 Antlr, Emacs Lisp 用的 Bovine/Wisent, C/C++ 用的 GNU Bison 等等.
除了通过使用的平台(语言)分类以外,可以通过解析算法进行划分,比如 LL(1), LR(1), LALR(1) 等等.
个人推荐可以学习一下 Bison 的使用,因为不少它的移植,比如上面的 Wisent 就是其中之一.这里有一篇简单完整的实践可以阅读一下.
解析器是一个挺大的话题,如果想了解更多这一方面的内容,可以看这一篇维基文章: Comparison of parser generators.
Scanning
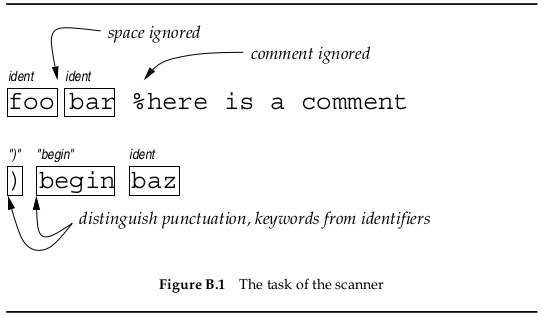
tokens 一定要是原子,也就是不可再划分,这需要根据部分的语言规范(the part of language specification)来划分,这部分的语言规范叫做词法规范(lexical specification).
如果是在BNF或者Grammar的描述中,tokens就是terminals.
典型的词法规范有3个:
- 空格序列(
sequence of spaces)和换行(newlines)都是等于一个空格. - 注释(comment),从某个标记符号开始到换行为止.
- 标识符(
identifier),以字母(letter)开头的字母和数字组成的序列.
Scanner 可以交给生成器来生成,不用自己写,只需要列出词法规范就可以用生成器完成工作,一般用正则表达式就可以编写规范.
不过使用的不是传统的正则表达式,是 Sllgen 附录中定义的正则表达式,个人觉得挺好的,就大概翻译一下,这门正则表达式的定义如下,
R :: = Character | R R | R ∪ R | R ∗ | ¬ Character
c匹配由一个c字符组成的字符串.¬ c匹配c以外的字符R S匹配字符串R后面跟着字符串S,这叫做concatenation.R ∪ R匹配R或者S,也可以写作R|S,叫做alternation.R*匹配由n(n >= 0) 个字符串R组成的字符串.这叫做R的Kleene closure.
当 scanner 找到一个 token,它就返回一个包含以下数据的数据结构:
class,token的类型.datum,token的数据.token在输入文本/源代码中的位置.
我直接采用 EOPL 第三章的 LET 语言做为例子, LET 的词法规范如下,
whitespace = (space|newline)(space|newline)* comment = %(¬ newline)* identifier = letter (letter|digit)* number = (-|"")digit digit*
现在为 scanner 定义这个规范,
(define the-lexical-spec '([whitespace (whitespace) skip] [comment ("%" (arbno (not #\newline))) skip] [identifier (letter (arbno (or letter digit "_" "-" "?"))) symbol] [number (digit (arbno digit)) number] [number ("-" digit (arbno digit)) number]))
Sllgen 的 scanner 规范要满足这个 BNF 语法,也是和正则表达式差不多,
Scanner-spec :: = ({Regexp-and-action}∗)
Regexp-and-action :: = (Name ({Regexp}∗) Action)
Name :: = Symbol
Regexp :: = String | letter | digit | whitespace | any
:: = (not Character) | (or {Regexp}∗)
:: = (arbno Regexp) | (concat {Regexp}∗)
Action :: = skip | symbol | number | string
Action 部分是指匹配的时候应该执行什么操作, skip 是指不操作并且不提交匹配 token.
symbol, number, string 分别是把匹配结果转成对应 Racket 的数据类型并且提交 token.
Parsing
得到 tokens 后就可以把它们转成 AST,这么一步要求知道语言的句法结构,也被叫做上下文无关语法(context-free grammar),可以通过 BNF 进行定义.
LET 的 grammar 定义如下,
A-program :: = Expression
Expression :: = Identifier
:: = Number
:: = - (Expression , Expression)
:: = zero? (Expression)
:: = if Expression then Expression else Expression
:: = Identifier
:: = let Identifier = Expression in Expression
现在定义这个语法,
(define the-grammar '([program (expression) a-program] [expression (number) const-exp] [expression ("-" "(" expression "," expression ")") diff-exp] [expression ("zero?" "(" expression ")") zero?-exp] [expression ("if" expression "then" expression "else" expression) if-exp] [expression (identifier) var-exp] [expression ("let" identifier "=" expression "in" expression) let-exp]))
Sllgen 的 grammar 的定义要满足如下语法,
Grammar :: = ({Production}∗)
Production :: = (Lhs ({Rhs-item}∗) Prod-name)
Lhs :: = Symbol
Rhs-item :: = Symbol | String
:: = (arbno {Rhs-item}∗)
:: = (separated-list {Rhs-item}∗ String)
Prod-name :: = Symbol
在 Sllgen 里面, 在知道 查找的哪一个 nonterminal 和 字符串的第一个token 后, grammar 要让 parser 判断出在使用哪一个 production.这种 grammar 就是 LL(1) 语法.
(这方面我个人没有什么了解,有错误的话可以提醒或者等我以后发现了修正.)
而 Sllgen 就是 Racket/Scheme 的一个 LL(1) parser generator.
上面的定义可以用于之后生成以下定义, 这里给它一个外号,定义B ,就是根据这些定义构成 AST,(我曾经按照书上的步骤使用 define-datatype,直到我看到了配套的源代码…)
(define-datatype program program? [a-program (exp1 expression?)]) (define-datatype expression expression? [const-exp (num number?)] [diff-exp (exp1 expression?) (exp2 expression?)] [zero?-exp (exp1 expression?)] [if-exp (exp1 expression?) (exp2 expression?) (exp3 expression?)] [var-exp (var identifier?)] [let-exp (var identifier?) (exp1 expression?) (body expression?)])
define-datatype 的形式如下,
(define-datatype type-name type-predicate-name
{(variant-name {(field-name predicate)}∗)}+)
准备完毕
上面的两个部分已经准备好了 Sllgen 需要的参数了,可以开始正式使用 Sllgen 完成语言实现中第一步的所有工作.
生成定义B
(sllgen:make-define-datatypes the-lexical-spec the-grammar)
生成 Scanner
(define just-scan (sllgen:make-string-scanner the-lexical-spec the-grammar))
生成 Parser
(define scan&parse (sllgen:make-string-parser the-lexical-spec the-grammar))
定义 REPL
(define read-eval-print (sllgen:make-rep-loop "--> " (lambda (ast) (value-of-program ast)) (sllgen:make-stream-parser the-lexical-spec the-grammar)))
value-of-program 也就是直译器的核心部分,语言实现的第二部分,这里就不写了,自己看书.
完整的例子
注意: 由于没有实现 interpreter,所以 parsing 后就直接返回 AST.
;; lang.rkt #lang racket ;; grammar for the LET language (require eopl) (provide (all-defined-out)) ;;;;;;;;;;;;;;;;;; grammatical specification ;;;;;;;;;;;;;;;;;; (define the-lexical-spec '([whitespace (whitespace) skip] [comment ("%" (arbno (not #\newline))) skip] [identifier (letter (arbno (or letter digit "_" "-" "?"))) symbol] [number (digit (arbno digit)) number] [number ("-" digit (arbno digit)) number])) (define the-grammar '([program (expression) a-program] [expression (number) const-exp] [expression ("-" "(" expression "," expression ")") diff-exp] [expression ("zero?" "(" expression ")") zero?-exp] [expression ("if" expression "then" expression "else" expression) if-exp] [expression (identifier) var-exp] [expression ("let" identifier "=" expression "in" expression) let-exp])) ;;;;;;;;;;;;;;;;;; sllgen boilerplate ;;;;;;;;;;;;;;;;;; (sllgen:make-define-datatypes the-lexical-spec the-grammar) (define show-the-datatypes (lambda () (sllgen:list-define-datatypes the-lexical-spec the-grammar))) (define scan&parse (sllgen:make-string-parser the-lexical-spec the-grammar)) (define just-scan (sllgen:make-string-scanner the-lexical-spec the-grammar)) ;; BUG bug here, do not use this function (define read-eval-print (lambda ([interpreter (lambda (ast) ast)]) ((sllgen:make-rep-loop "--> " interpreter (sllgen:make-stream-parser the-lexical-spec the-grammar)))))
再来一个手动测试,
racket@lang.rkt> (read-eval-print) --> -(1,2) #(struct:a-program #(struct:diff-exp #(struct:const-exp 1) #(struct:const-exp 2))) -->
这个就是经过格式化的 AST,
#(struct:a-program
#(struct:diff-exp
#(struct:const-exp 1)
#(struct:const-exp 2)))
可以看到每一个节点都是 syntax object,因此 每一个节点都包含它们的结构体类型,数据以及位置,刚好满足了上面的要求.