图形学 - OpenGL坐标变换
Table of Contents
之前只讲了几何变换,也就是最简单的变换,本文主要透过 OpenGL 的各种坐标系来讲解图形学的渲染管线的坐标系是如何转换的,这对于理解 OpenGL 的渲染管线/渲染流水线(rendering pipeline)很有必要.
不过我不打算花重笔写渲染管线的内容,因为渲染管线会随着 OpenGL 的升级而改变, OpenGL 1.X 到 OpenGL 2.X 就经历一次重大改变: 固定管线被移除(fixed function pipepline),取而代之的是可编程管线(programmable pipeline),
OpenGL Shader Language (GLSL) 也是从这个版本出来的,其实也就是固定管线的一部分环节"放开权限"给开发人员编码,所以从 OpenGL 1.X 开始学习也是没问题的,
关于更多的本版变迁问题,可以在官方维基的这个页面看到,本文是按照 1.X 渲染管线来写的, OpengL 1.X 渲染管线的文章有很多,比如这里这一篇,还是同一位作者,本文是参考了他的这篇文章: OpenGL Transformation 写的.
本文只会写渲染管线的两个环节: Vertex Operation 以及 Primitive Assembly,它们背后的数学原理,这是后面学习 GLSL 是必须的知识基础.
几个该清楚的概念
齐次空间
欧几里得空间+笛卡尔坐标系这样的组合中,两条平行的直线是永远不可能相交的,这是不符合人的视觉的,但在人看来,也就是在投影空间(projective space)却会相交.

Figure 1: 马路两边的两条平行线在原处相交(图片来源于网络)
为了解决计算问题,数学家给投影空间找到一种坐标系:齐次坐标系(Homogeneous coordinate system).所以投影空间又叫齐次空间(Homogeneous space).
齐次空间是用来处理投影空间上的图形以及几何的计算.齐次坐标就是 \(n\) 维坐标的 \(n+1\) 维坐标表示,是投影空间也基于向量空间.
一个 2D 的笛卡尔坐标 \(\left(x, y\right)\) 的齐次坐标是这样的 \(\left(x_{'}, y_{'}, w\right)\),其中满足这样的关系 \(\begin{equation*} \left\{ \begin{aligned} x &= \frac{x_{'}}{w} \\ y &= \frac{y_{'}}{w} \end{aligned} \right. \end{equation*}\).
一个笛卡尔坐标 \(\left(1, 2\right)\) 在齐次坐标系上可以用 \(\left(1, 2, 1\right)\), \(\left(2, 4, 2\right)\) … 表示,不管用哪种方式表示,它们都对应同一个笛卡尔坐标,所以这些点都是"homogeneous",所以它们都叫做"homogeneous coordinates".
当 \(\left(1, 2\right)\) 向原处无限移动,相当于 \(w = 0\), \(\left(\frac{1}{0}, \frac{2}{0}\right) \approx \left(\infty, \infty\right)\).
这里结合仿射空间来理解,你可能会发现这不就是仿射变换吗?答案也的确如此,一个三维的点可以看成一个二维的点平移到平面外所得到的结果.所以说, 仿射空间由向量空间派生得来,而投影空间由仿射空间派生得来.
如何证明两条平行线可以相交呢?
假设现在在笛卡尔坐标系中有这这样的方程组: \(\begin{equation*} \left\{ \begin{aligned} Ax + By + C = 0 \\ Ax + By + D = 0 \end{aligned} \right. \end{equation*}\), 如果 \(C \neq D\), 那么该方程组无解(因为平行无法相交),如果 \(C = D\),那么两条线是重叠的,或者说就是同一条线.
把它改写成投影空间上的关系: \(\begin{equation*} \left\{ \begin{aligned} A\frac{x^{'}}{w} + B\frac{y^{'}}{w} + C = 0 \\ A\frac{x^{'}}{w} + B\frac{y^{'}}{w} + D = 0 \end{aligned} \right. \longrightarrow \left\{ \begin{aligned} Ax^{'} + By^{'} + Cw = 0 \\ Ax^{'} + By^{'} + Dw = 0 \end{aligned} \right. \end{equation*}\).
现在这个方程组有一个解: \(\left(x^{'}, y^{'}, 0\right)\),因为 \(\left(C - D\right)w = 0\), 所以 \(w = 0\), 所以它们会在 \(\left(x^{'}, y^{'}, 0\right)\) 上相交.
对于 3D 也是适用的,都是增加额外一个维度,不过这个额外的维度意义重大,它引入了透视这个概念,为 3D 坐标映射到 2D 坐标提供了可能(总得来说提供了高维度到低一维度转变的可能).
其实 \(w\) 分量还有有区分点(points)与向量(vectors)的作用.
假设有一个表达式 \(P = \left(x, y, z\right)\), 在没有特殊说明下, 人们无从得知 \(P\) 是位置(position)还是方向(direction),
因为位置和方向的表示都一样. 因此人们添加 \(w\) 作为标识用来区分:
\(P = \left(x, y, z, w\right)\).
当 \(w = 0\) 时, \(P\) 就是方向, 否则 \(P\) 就表示位置.
这并非只是作为标识那么简单, \(w\) 的值也的确会影响计算结果.
假设有一个 \(4 \times 4\) 的矩阵 \(M = \left( \begin{array}{c} x_1 & y_1 & z_1 & w_1 \\ x_2 & y_2 & z_2 & w_2 \\ x_3 & y_3 & z_3 & w_3 \\ x_4 & y_4 & z_4 & w_4 \end{array} \right)\), 要计算 \(MP\),
当 \(w = 0\) 时相当于 \(M\) 的第 4 列 \(\left( \begin{array}{c} w_1 \\ w_2 \\ w_3 \\ w_4 \end{array} \right)\) 可直接被忽略.
在几何变换中, \(M\) 的第 4 列负责平移变换部分, \(w = 0\) 则可以忽略平移变换, 这对于方向来说是合理的, 因为方向与位移无关.
因此, 在进行变换时需要明确变换的对象, 确定好 \(w\) 的值.
更多关于齐次空间的内容可以参考这些资源:
http://morpheo.inrialpes.fr/people/Boyer/Teaching/M2R/geoProj.pdf
有涉及到欧几里得空间,仿射空间还有投影空间三者的关系,还有不同变换的效果的直观展示.
http://kahrstrom.com/mathematics/documents/OnProjectivePlanes.pdf
直接给出了相关概念的定义,可以作为参考.
平面方程
这里先约定一下: 从原点出发到 \(p\) 的向量会采用 \(\vec{p}\) 这种方式表示, \(p\) 就单纯表示点,如果是从 \(p_{1}\) 出发到 \(p_{2}\) 的向量就用 \(\vec{p_{1}p_{2}} = p_{2} - p_{1}\) 表示.
在欧几里得空间中,指定任意平面 \(P\) 的某个点 \(p_{1}\), 从该点的位置延伸一条法线向量 \(\vec{n} = \left(a, b, c\right)\),(可以从任意点延伸出相同方向的法线变量),
该法线向量表示了平面 \(P\) 的面向方向,而 \(p_{1}\) 确定了平面的位置,可以反过来说 \(p_{1}\) 和 \(\vec{n}\) 确定了 \(P\),
可以想像成一根棒子 \(\vec{n}\) 从木板 \(P\) 的 \(p_{1}\) 点位置垂直穿过,如图所示,
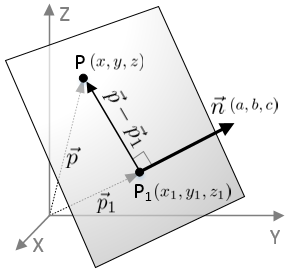
因为平面 \(P\) 不包含原点,所以可以把它看做一个仿射空间,在该空间上, \(p_{1}\) 和 \(p\) 分别是已知的点和 任意的点, 而不是从原点出发的向量, 并且 \(p_{1}\) 和 \(p\) 构成直线(向量):
\(p - p_{1} = \left(x - x_{1}, y - y_{1}, z - z_{1}\right)\).
因为 \(\vec{n}\) 垂直平面 \(P\),所以也垂直与 \(P\) 上的任意直线(向量), 所以关系成立 \(\vec{n} \cdot \left(p - p_{1}\right) = 0\),这个就是平面方程 (plane equation),可以用来表示平面 \(P\).根据这条等式可以得到:
\(\left(a, b, c\right) \cdot \left(x - x_{1}, y - y_{1}, z - z_{1}\right) = 0\)
\(a\left(x - x_{1}\right) + b\left(y - y_{1}\right) + c\left(z - z_{1}\right) = 0\)
\(ax + by + cz - \left(ax_{1} + by_{1} + cz_{1}\right) = 0\).
反过来说, 如果点 \(v\) 满足 \(P \cdot v = 0\),那么 \(v\) 就属于平面 \(P\) 上.
因为 \(\vec{p_{1}}\) 和 \(\vec{n}\) 是共线且同向的,所以它们关系满足 \(\vec{p_{1}} = k \cdot \vec{n} = \left(ka, kb, kc\right)\), \(k\) 是一个常量,也就是说 \(ax + by + cz - k \cdot \left(a^{2} + b^{2} + c^{2}\right) = 0\).
实际上平面方程还有一个含义: 那么就是点 \(p\) 到平面 \(P\) 的距离 \(ax + by + cz - k \cdot \left(a^{2} + b^{2} + c^{2}\right)\) 为 0.
按照这个含义, \(ax + by + cz - k \cdot \left(a^{2} + b^{2} + c^{2}\right)\) 就是点 \(p\) 到平面 \(P\) 的距离.
但这个距离是有正负的, 因此这个距离也被称为符号距离(signed distance), 这里先把它称呼为
SD;所以, \(SD = ax + by + cz - k \cdot \left(a^{2} + b^{2} + c^{2}\right)\).
那么这个
SD有什么用呢? 它可以用来判断点 \(p\) 与平面 \(P\) 之间的相对位置.比如, \(SD \gt 0\) 表示 \(p\) 在 \(P\) 的正面, \(SD = 0\) 表示 \(p\) 在 \(P\) 里面, \(SD \lt 0\) 表示 \(p\) 在 \(P\) 的背面;
当然, "正为正, 负为背" 的情况也可以相互反过来, 具体看人们如何定义.
如果 \(\vec{n}\) 是单位向量,因为 \(a^{2} + b^{2} + c^{2} = 1\),所以整个等式变为 \(ax + by + cz - k = 0\),这种情况下 \(k\) 就是平面 \(P\) 到原点的距离 \(d\) 了,
而 \(d = - \left(ax_{1} + by_{1} + cz_{1}\right)\),那么等式变成 \(ax + by + cz + d = 0\).
根据上面说过的可根据方向以及平面到原点的距离确定平面, 也就是平面 \(P\) 可以由 \(\vec{n}\) 和 \(d\) 决定,
可以通过齐次空间的角度来看待平面 \(P\), 平面 \(P\) 由经过原点的平面 \(P^{'}\) 沿着它面向的方向平移距离 \(d\) 得到, \(P = \left(\begin{array}{c|c}\vec{n} | d\end{array}\right) = \left(a, b, c, d\right)\).
假设点 \(p = \left(x, y, z, w\right)\) 满足 \(P \cdot p = ax + by + cz + dw = 0\), 那么点 \(p\) 就在平面 \(P\) 上.
这里 \(d = \frac{-\left(ax_{1} + by_{1} + cz_{1}\right)}{w}\),如果 \(w = 1\),那整个等式就和欧几里得空间下的平面方程一样.
总结一下, 只要有一个平面上的任意点 \(p = \left(x_{1}, y_{1}, z_{1}\right)\) 和该平面的法线向量 \(\hat{n} = \left(a, b, c\right)\), 那么就能确定一个平面方程:
\(ax + by + cz + dw = 0\), 其中 \(d = \frac{-\left(\vec{n} \cdot p\right)}{w}\), 而 \(w\) 是 \(p\) 点的齐次坐标版本 \(p^{'} = \left(\begin{array}{c|c}p | w\end{array}\right)\) 的 \(w\) 分量.
虽然有提到过, 但还是重申一下:
人们会用 \(w\) 不为零来表示 \(p^{'}\) 是点坐标, 而不是向量. 当 \(w = 1\) 时, \(d\) 平移变换才有意义,
因此, 有时候人们会把坐标的 \(w\) 分量变为 0 后再应用矩阵, 从而消除矩阵中的平移变换.
OpenGL 中对象的变换历程

Figure 2: OpenGL vertex transformation
理解其中的每个环节对以后掌握编写 Shader 是十分有必要的:其中发生了什么,要怎么计算.
比如在学习 GLSL 的编写时,通常会有说某个坐标是什么坐标系,意思就是这个坐标系是通过了什么变换后得到的结果,
比如坐标用的世界坐标系,那么它就是顶点经过模型变换得到的结果;
再比如坐标用的是视点坐标系,那么它就是顶点先经过模型变换然后再经过视点变换得到的结果,等等.
如果这些都不理解的话,很容易会因为用错坐标系得到错误的计算结果,比如在以后的光照计算中.
但需要明确一点, OpenGL 本身没有具体定义这些变换, 不同的 OpenGL 库会有不同的具体实现,
具体差异在于坐标空间的坐标系不一样, 本文只会选取其中一种实现进行学习,
因此, 本文的矩阵不一定与库实现的矩阵一致, 在参考本文时需要注意坐标系区别, 当然矩阵的推导思路基本上是一样的.
对象坐标系
用来画对象(object),或者说指定顶点(vertex)的坐标系叫做对象坐标系(object coordinate system).
也有人称之为局部坐标系(local coordinate system), 其实我更跟喜欢这个叫法, 因为局部这个词语更突出个体和环境之间的关系.
对象/局部坐标系其实是一个统称, 只要一个坐标系和所描述对象的相对位置始终保持不变, 那么这个坐标系就可以被称为局部坐标系.
这个对象(个体)并不一定只能是顶点, 还可以是其它对象, 前面之所以把描述
3D物体的顶点的坐标系等同于对象/局部坐标系,是因为后面的一些列变换都是针对顶点进行的. 但为了杜绝以后出现概念上误解的一切可能性, 我觉得这里有必要强调一番,
而且后面还会见到其它类型的局部坐标系.
我们假设在该坐标系下有一个点 \(p_{o} = \left(x_{o}, y_{o}, z_{o}\right)\), 让我们来探讨一下这个点会经历过哪些变化.
世界坐标系
在 OpenGL 中,复杂的对象是由简单的对象构成的,最简单的对象叫做图元(primitive),一旦画出对象接下来就由两种可能,
A. 把不同对象组装成更加复杂的对象.
B. 把对象放到场景(scene)/世界(world)中.
场景/世界就是所有对象里面最复杂,最大的那个对象,定义场景/世界的坐标系叫做世界坐标系(world coordinate system),
本质就是一个对象坐标系. 我们把这个坐标系统上的所有的点的集合叫做世界空间(world space).
和局部坐标系相对应, 世界坐标系也被称为全局坐标系(global coordinate system).
从对象坐标系到世界坐标系的变换
上面中, \(A\) 过程中对象是经历了从一个对象坐标系到另外一个对象坐标系的变换, \(B\) 过程是对象经历了从对象坐标系到世界坐标系的变换,
本质都是从 一个对象坐标系到另外一个对象坐标系的变换,这种变换叫做模型变换(modeling transformation),
因此在 OpenGL 中对象坐标系以及世界坐标系只是概念上的区别,没有这两种概念的对应实现.
用 \(M_{model} = \left(\begin{array}{c} m_{1x} & m_{2x} & m_{3x} & d_{x} \\ m_{1y} & m_{2y} & m_{3y} & d_{y} \\ m_{1z} & m_{2z} & m_{3z} & d_{z} \\ 0 & 0 & 0 & 1\end{array}\right)\) 表示这个模型变换.
其中 \(\left(\begin{array}{c}m_{1x} \\ m_{1y} \\ m_{1z}\end{array}\right)\), \(\left(\begin{array}{c}m_{2x} \\ m_{2y} \\ m_{2z}\end{array}\right)\) 以及 \(\left(\begin{array}{c}m_{3x} \\ m_{3y} \\ m_{3z}\end{array}\right)\) 分别是 \(x\), \(y\) 以及 \(z\) 轴, 至于 \(\left(\begin{array}{c}d_{x} \\ d_{y} \\ d_{z} \end{array}\right)\) 是负责平移.
通过一个 2D 例子想象一下 ,我们已经画了一个三角形,要把它放到已经画好的正方形上,它们都有各自的坐标系,
也就是上面提到的对象坐标系, 通常来说都希望系统对象都是居中到坐标系的中心, 也就是原点上,
或者至少使用原点作为参考点(reference point), 首先把三角形放到正方形的原点上,然后 通常 按照缩放,
旋转以及平移这个顺序参考正方形的坐标系原点进行几何变换, 按照这个顺序变换是因为缩放和旋转不会让三角形偏移参考点,
而平移是会偏移参考点的,如果先平移再缩放和旋转的话, 直接按照参考点进行缩放和旋转会出现问题.
本质上来说, 模型变换属于几何变换/坐标变换, 并不属于基底变换.
这个阶段结束后会得到一个变换过的点 \(p_{m} = M_{model}p_{o} = \left(x_{m}, y_{m}, z_{m}\right)\).
视点坐标系
在现实中,一个人看到的东西是由他的位置以及看的方向所决定的,在 OpenGL 中也有类似的存在,叫做 viewer,
它有自己的坐标系用来描述它的位置以及看的方向,这个坐标系叫做视点坐标系(eye coordinate system).
OpenGL 并没有明确定义视点坐标系是左手系还是右手系, 具体要看 OpenGL 库的实现. 这里以右手坐标系进行学习.
而 viewer 就是作为坐标系的原点 \((0, 0, 0)\), viewer 其实就是 OpenGL 的相机(camera),
但实际上 OpenGL 但没有定义相机这个对象以及对应的变换,所以如果要看场景的其他位置,
只能对整个场景进行反向模型变换(比如看场景的右边,那么场景就需要向左边平移)来实现.
也就是说 OpenGL 的相机是虚拟的.
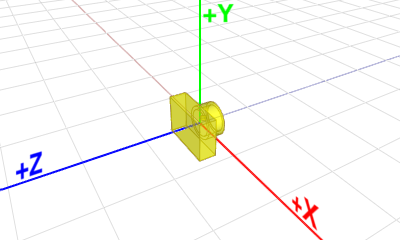
Figure 3: 视点坐标系
从世界坐标系到视点坐标系的变换
一旦模型变换完成后,就可以开始进行到视点坐标系的变换了,这个叫做视点变换(viewing transformation).
OpenGL 的相机是虚拟的, 它没有相应的顶点数据, 是对场景进行逆向变换来达到"变换相机"的效果.
举个例子, 我们要观察手中的一个物品, 由于想看得仔细一点, 通常都是把物体移动得靠近眼睛,
当然如果不是拿在手上的话, 把头凑过去或者靠近过去也能观察得仔细一点;
如果想看物体的左侧面, 通常是让物体右转, 同样, 如果不是拿在手上, 我们自己绕到它的左边也能看到它的左侧面.
这里例子可以把我们自己的头部比作相机, 物体看作整个场景, 手持移动物意味着对物体的变换.
简单来说, 视觉上的变化和物体上的变化是相反的, 当然, 在逻辑上相机本身也是场景上的物体, 对相机进行变换, 视觉上也是反的.
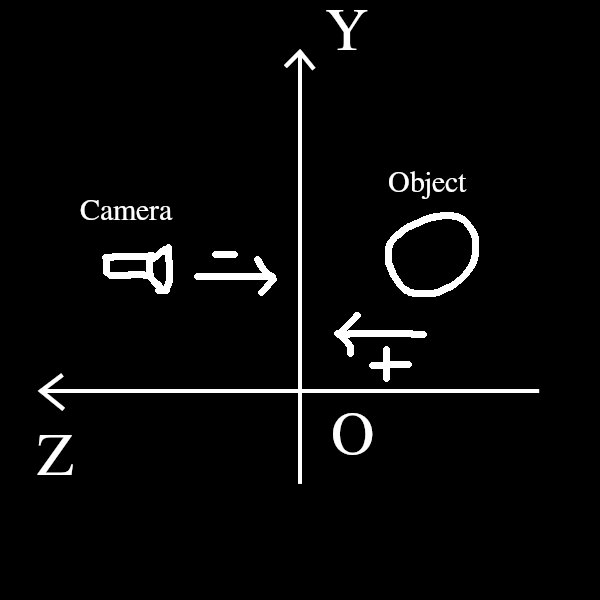
Figure 4: 物体平移上在视觉上的相反: 当相机往原点平移时, 物体在视觉上也是往原点平移, 双方平移的方向相反.
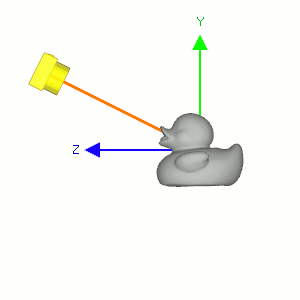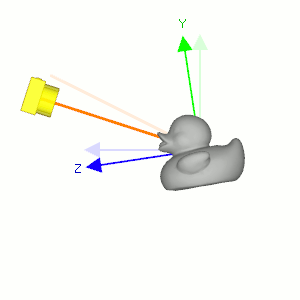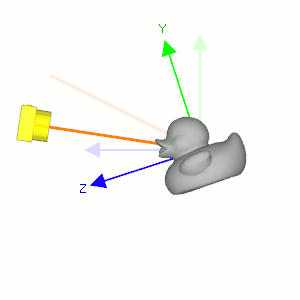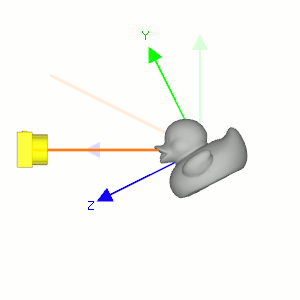
Figure 5: 固定相机的位置使它看着原来的方向(浅色橙线), 让小黄鸭围绕自身对象坐标系的 \(x\) 轴往逆时针方向旋转, 相当于相机围绕小黄鸭的对象坐标系 \(x\) 轴往顺时针方向旋转.
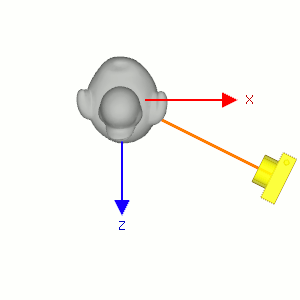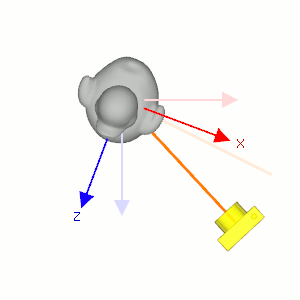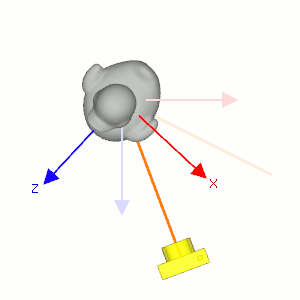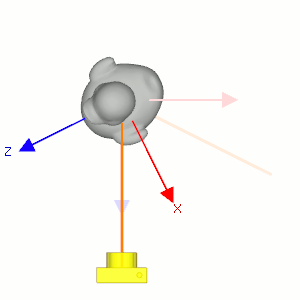
Figure 6: 固定相机的位置使它看着原来的方向(浅色橙线), 让小黄鸭围绕自身对象坐标系的 \(y\) 轴往顺时针方向旋转, 相当于相机围绕小黄鸭的对象坐标系 \(y\) 轴往逆时针方向旋转.
视点变换就是相机模型变换的逆变换, 相机的缩放变换被认为是不合逻辑的, 所以只考虑相机模型的平移和旋转变换即可.
综上所属, 假设 \(M_{camera} = M_{T}M_{R}\) 是相机的模型变换, 其中 \(M_{T}\) 是相机的平移, \(M_{R}\) 是相机的旋转,
那么视点变换就是 \(M_{view} = M_{camera}^{-1} = M_{R}^{-1} R_{T}^{-1}\).
视点变换和前面的模型变换不同, 视点变换属于基底变换, 这种变换不会修改顶点的位置, 只会修改坐标系,
这也能解释为什么视点变换是相机模型变换的逆变换, 因为基底变换与坐标变换就是互相变换.
由于在编码中直接以矩阵作为参数实在是有点麻烦, 而且对于领域外的开发人员来说不够直观,
所以 OpenGL 提供了一个名为 \(lookAt\) 的函数来构建这个矩阵, 这个函数参数全都是世界坐标系上的向量:
- \(eye\) - 指定相机的位置
- \(center\) - 相机看向的位置
- \(up\) - 指定相机大概的朝上方向
根据这些参数, 很简单地就找到 \(M_{T}^{-1} = \left(\begin{array}{c} 1 & 0 & 0 & - x_{center} \\ 0 & 1 & 0 & - y_{center} \\ 0 & 0 & 1 & - z_{center} \\ 0 & 0 & 0 & 1 \end{array} \right)\).
而 \(M_{R}^{-1}\) 就不太好看出来了, 因为仅凭这三个参数不足以解析相机是围绕哪根轴往什么方向旋转了多少度,
所以通过旋转矩阵来构建 \(M_{R}^{-1}\) 不现实.
这里的视点坐标系是一个右手正交坐标系, 其 \(z\) 轴的正方向可通过参数 \(eye\) 和 \(center\) 计算出来,
再加上也有相机朝上的方向 \(up\), 利用好叉积就可以构建出这个坐标系.
首先, 算出相机的"视线"方向:
\(forward = eye - center \rightarrow \hat{f}_{\text{right-hand}} = \frac{forward}{|forward|}\),
\(\hat{f}_{\text{right-hand}}\) 是指向右手坐标系的 \(z\) 轴正方向的, 以后将会作为新坐标系上的 \(z\) 轴;
然后, 用 \(\hat{f}_{\text{right-hand}}\) 或者 \(forward\) 与向量 \(up\) 进行叉积, 求出同时垂直于它们的向量:
\(right = up \times \hat{f}_{\text{right-hand}} \rightarrow \hat{r}_{\text{right-hand}} = \frac{right}{|right|}\),
根据几何关系, \(up\) 是围绕 \(\hat{r}_{\text{right-hand}}\) 以逆时针方向旋转到达 \(\hat{f}_{\text{right-hand}}\) 方向上, 所以 \(\hat{r}_{\text{right-hand}}\) 会作为新坐标系上的 \(x\) 轴正方向.
最后, \(up\) 并不一定与 \(\hat{f}_{\text{right-hand}}\) 正交, 所以它并不能作为 \(y\) 轴正方向,
要构建出一个同时垂直于 \(\hat{f}_{\text{right-hand}}\) 和 \(\hat{r}_{\text{right-hand}}\) 的向量 \(\hat{u}_{\text{right-hand}}\) 作为 \(y\) 轴, 根据几何关系可得:
\(\hat{u}_{\text{right-hand}} = \hat{f}_{\text{right-hand}} \times \hat{r}_{\text{right-hand}}\),
也就是 \(\hat{f}_{\text{right-hand}}\) 围绕 \(\hat{u}_{\text{right-hand}}\) 以逆时针方向旋转 \(90^{\circ}\) 到达 \(\hat{r}_{\text{right-hand}}\), 因此, \(\hat{f}_{\text{right-hand}} \times \hat{r}_{\text{right-hand}}\) 本身就是单位向量.
令 \(\hat{r}_{\text{right-hand}} = \left( \begin{array}{c} x_r \\ y_r \\ z_r \end{array} \right)\), \(\hat{u}_{\text{right-hand}} = \left( \begin{array}{c} x_u \\ y_u \\ z_u \end{array} \right)\), \(\hat{f}_{\text{right-hand}} = \left( \begin{array}{c} x_f \\ y_f \\ z_f \end{array} \right)\), 把它们组合成得到 \(M_{R} = \left( \begin{array}{c} x_r & x_u & x_f & 0 \\ y_r & y_u & y_f & 0 \\ z_r & z_u & z_f & 0 \\ 0 & 0 & 0 & 1 \end{array} \right)\),
由于 \(M_{R}\) 是一个旋转矩阵, 而旋转矩阵是正交矩阵, 正交矩阵的逆矩阵就是它的转置矩阵, 所以 \(M_{R}^{-1} = \left( \begin{array}{c} x_r & y_r & z_r & 0 \\ x_u & y_u & z_u & 0 \\ x_f & y_f & z_f & 0 \\ 0 & 0 & 0 & 1 \end{array} \right)\).
这并非唯一的构建方案, 比如下面这个参考资料中的视点变换把 \(z\) 轴的方向反转了:
https://registry.khronos.org/OpenGL-Refpages/gl2.1/xhtml/gluLookAt.xml
到了这一步,整个 Vertex Operation 环节就完成了.
在 OpenGL 里面,模型变换和视点变换是集成为一个阶段.
最后会得到一个新的坐标点 \(p_{e} = M_{view}p_{m} = \left(x_{e}, y_{e}, z_{e}\right)\).
法线向量变换
别忘记还有光线的存在,如果开发人员启用了光照(lighting)那么就得计算光线,
但是模拟现实光线的运算量是十分大的,目前的硬件条件下只能对现实光线进行简化或者另外一种取代方案,这个方案用到法线向量.
法线向量变换在光照计算有着十分重要的作用, 目前先了解 OpenGL 中的法线向量, 法线向量的信息与顶点是一对一的关系,
这和在数学中学到的不一样: 在三维空间中, 点没有方向, 没有点与线/面之间垂直的说法.
在图形学中, 点更多是看作是面的边缘的一个小片段, 便有了方向这一属性.
比如 graphicsbook 这里的例子:

这两个实际上是同一个几何体(由多个长方形平面构成),但是由于法线向量的不同导致看起来不一样,前者更光滑(smooth),后者更扁平(flat).
它们的法线分布分别是这样的,
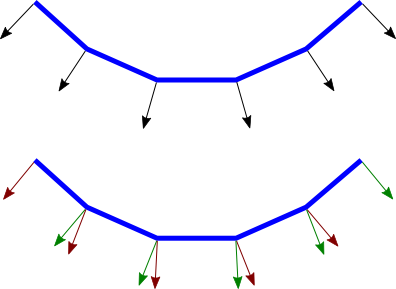
可以看出一个顶点可以拥有不止一个法线向量,两种不同的法线向量分配方法反映了对一个几何体的不同看法:
前者是把几何体看做一个整体表面,而不是一个一个长方形,近似地为每个顶点添加法线向量(Normal Per Vertex);后者是把几何体看做一个一个长方形,为每个平面添加法线(Normal Per Face).
这两种分布方法分别叫做 Smooth shading 和 Flat shading,如果是为了突出整体表面,那么就用 Smooth shading,如果是为了突出几何体不同的面就用 Flat shading.
现在开始了解法线向量的变换,这里用单个平面作为例子开始着手.
OpenGL 会先找出顶点 \(v_{1}\) 附近的其它顶点(\(v_{2}\) 和 \(v_{3}\)),这些顶点能够构成平面,三个顶点就能确定一个平面了,根据这些点构成的平面就能计算出平面的法线向量 \(\vec{n}\) (就是用三个点构造出两个向量,然后通过这两个向量的叉积求出法线向量),
它就是顶点(\(v_{1}\), \(v_{2}\) 和 \(v_{3}\))的法线向量了,为了到光照计算得到正确结果, OpenGL 要求法线向量规范化,也就是变成单位向量.
要注意,\(\vec{n}\) 是同时垂直于三个顶点才能说垂直于其中某一个顶点,同时垂直于三个顶点意味垂直三个顶点所处的平面上(所以这并非说 \(\vec{n}\) 垂直于 \(\vec{v_{1}}\) 这条由原点和顶点 \(\vec{v_{1}}\) 定义的直线, \(v_{2}\), \(v_{3}\) 同理).
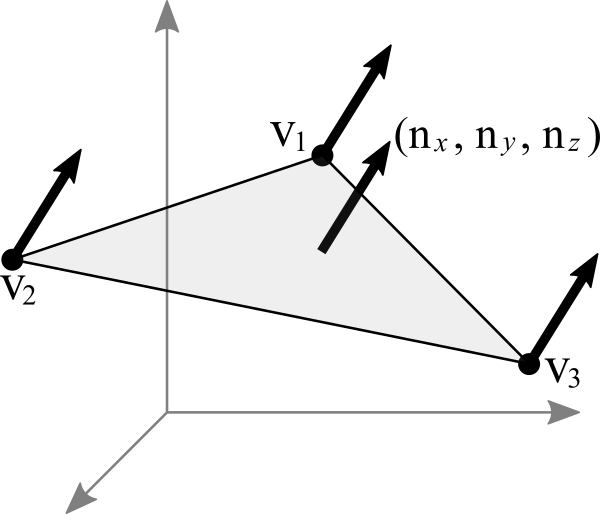
由于光照计算是需要视点坐标系下的法线向量的, 所以需要思考的问题是: 如果三个顶点发生经过 \(M_{modelview}\) 变换后,\(\vec{n}\) 会发生什么变化呢?
可以肯定的是 \(\vec{n}\) 和 \(v_{1}\), \(v_{2}\) 以及 \(v_{3}\) 的经历的变换肯定是不一样的, 找个反例就知道了, 假设 \(v_{1} = \left(1, 0, 0\right)\) 和 \(v_{2} = \left(0, 1, 0\right)\), 它们的法线向量 \(\vec{n}\) (假设是单位向量) 满足 \((v_{2} - v_{1})\cdot \vec{n}\), 所以 \(\vec{n} = \left(0, 0, 1\right)\),
沿 \(y\) 轴正方向平移2个单位得到 \(v_{1} = \left(1, 2, 0\right)\) 以及 \(v_{2} = \left(0, 3, 0\right)\), 法线向量 \(\vec{n}\) 变成 \(\left(0, 0, 3\right)\), 而不是变成 \(\left(0, 2, 1\right)\), 换成单位向量标准来看法线向量的方向并没发生.
我们先换到齐次坐标系下看待这问题,根据法线向量 \(\vec{n}\) 构建出齐次平面 \(P = \left(\begin{array}{c|c} n & n_{w}\end{array}\right) = \left(n_{x}, n_{y}, n_{z}, n_{w}\right)\),该平面可看作由经过原点的平面 \(P^{'}\) 朝它面向的方向 \(\vec{n}\) 移动 \(n_{w}\) 距离后得到的.
\(v = \left(x, y, z, w\right)\) 是该平面上的任意一点,所以 \(P \cdot v = \left(\begin{array}{c} n_{x} & n_{y} & n_{z} & n_{w}\end{array}\right) \left(\begin{array}{c}x \\ y \\ z \\ w\end{array}\right) = 0\).
把这个平面方程改一下就可以推导出法线变换了: \(PM_{modelview}^{-1}M_{modelview}v = \left(\begin{array}{c} n_{x} & n_{y} & n_{z} & n_{w}\end{array}\right) M_{modelview}^{-1}M_{modelview} \left(\begin{array}{c}x \\ y \\ z \\ w\end{array}\right) = 0\).
其中 \(M_{modelview} \left(\begin{array}{c}x \\ y \\ z \\ w\end{array}\right)\) 就是我们前面提到从对象坐标变换到视点坐标的过程,那么 \(\left(\begin{array}{c} n_{x} & n_{y} & n_{z} & n_{w}\end{array}\right) M_{modelview}^{-1}\) 就是我们想要法线向量变换,这种写法可能会更加熟悉一点: \(\left(M_{modelview}^{-1}\right)^{T} \left(\begin{array}{c}n_{x} \\ n_{y} \\ n_{z} \\ n_{w}\end{array}\right)\).
整个方程是这样的意思: 从对象坐标到视点坐标变换得到的顶点 \(M_{modelview} \left(\begin{array}{c}x \\ y \\ z \\ w\end{array}\right)\) 是变换后的平面 \(\left(\begin{array}{c} n_{x} & n_{y} & n_{z} & n_{w}\end{array}\right) M_{modelview}^{-1}\) 上的一个点.
所以说白了,法线变换就是平面变换,下面这些是关于法线向量变换的额外的资料,有兴趣的可以看一下:
https://www.cs.upc.edu/~robert/teaching/idi/normalsOpenGL.pdf
http://www.glprogramming.com/red/appendixf.html
另外, 还有一些值得注意的点, 在涉及法线变换的计算中, \(M_{modelview}\) 中的平移变换是不影响法线的方向,
也就是说平移变换可以忽略. 同样, \(M_{modelview}\) 里面的缩放变换是等比缩放的(也就是 \(x\), \(y\), \(z\) 各个分量的缩放系数一致),
那么缩放变换只会影响法线长度, 不影响法线的方向, 也是可以一同忽略; 但如果缩放不等比, 法线的方向也会发生变化.
当这两个变换被忽略后得到的矩阵 \(M\) 就是剩下的物体旋转变换和相机旋转变换之间的乘积, 也就是两个正交矩阵之间的积,
而正交矩阵之间的积依然是正交矩阵, 因此可简单地通过转置就能求出 \(M\) 的逆矩阵.
另外, 这个推导结果也符合顶点法线不垂直于平面的情况, 只是平面方程变成这样 \(P \cdot v \ne 0\).
如果 \(P\) 和 \(v\) 是同时进行相同的变换, 那么它们的位置是相对固定的, 也就是说在变换后 \(P \cdot v\) 的值也依旧是一样的,
因此, \(P \cdot v \ne 0\) 并不影响后续的推导.
最后再提醒一下, 在固定管线的时期,
OpenGL的 \(M_{modelview}\) 是不能分开成 \(M_{model}\) 和 \(M_{view}\) 的,所以那个时期的法线变换只能是 \((M_{modelview}^{-1})^{T}\), 并且用于计算光照的光源是也是在视点坐标系上的.
后来可以对 \(M_{modelview}\) 进行拆分, 光源以及法线变换的发生都可以在世界坐标系上, 这个时候的法线变换为 \((M_{model}^{-1})^{T}\).
如果要在世界坐标系上进行计算法线的变换, 并且只考虑法线的方向, 那么可以使用以下方法进行计算:
如果 \(M_{model}\) 只包含了等比缩放和旋转, 就说明 \(M_{model}\) 是正交矩阵, 所以 \(M_{model}^{-1} = M_{model}^{T} \Rightarrow (M_{model}^{-1})^{T} = M_{model}\),
那么可以通过该计算得出法线方向: \(M_{model} \left(\begin{array}{c} n_x \\ n_y \\ n_z \\ n_w = 0 \end{array} \right)\).
法线贴图 (Normal Texture)
在了解发现贴图之前需要先了解什么是贴图(textures), 什么是贴图坐标/纹理坐标(texture coordiantes),
OpenGL是如何根据贴图坐标把贴图贴在平面上的. 这些概念是学习法相贴图相关数学知识的前提.我推荐通过 LearnOpenGL - Textures 这篇文章来了解前面提到的几个概念就足以, 不用看太多.
更多关于贴图的细节可以等到学习渲染的过程中再去了解.
法线贴图的目的是让平面上的每一处的法线都不一样, 前面章节中的法线是根据顶点计算出来的,
法线和顶点所处的平面成垂直关系; 而法线贴图中的法线并非如此: 法线和顶点所处的平面不一定成垂直关系.
顾名思义, 法线贴图是一张图, 每一个像素的颜色 \((r, g, b)\) 代表着一个法线向量 \((x, y, z)\).
这里做一点声明, 为了区分"用于表示平面方向的法线向量"和"从法线贴图读取的法线向量",
我们把前者叫做面法线 \(n_{plane}\), 把后者叫做法线向量 \(n_{texture}\).
在 OpenGL 里面颜色的每个分量的范围都是在 \([0, 1]\) 区间内, 这个区间实际上是从 \([0, 255]\) 映射过来的.
也就是说在其他软件上的白色 \((255, 255, 255)\) 到了 OpenGL 里面会变成 \((1, 1, 1)\).
法线向量每个分量的范围则是在 \([-1, 1]\) 内, 所以从法线贴图读取数据后要进行转换才能获得法线向量:
\(n_{texture} = (x, y, z) = (2 \times r - 1, 2 \times g - 1, 2 \times b - 1)\).
面法线 \(n_{plane}\) 是在对象坐标系上的, 但 \(n_{texture}\) 是在切线空间(Tangent Space)上的.
正如开头所说的, \(n_{texture}\) 不一定与顶点所处的平面垂直, 这说明 \(n_{texture}\) 不一定根据顶点计算出来的,
因此 \(n_{texture}\) 不像 \(n_{plane}\) 那样与顶点之间存在关系, 但切线空间是根据顶点计算出来的,
也就是该空间与顶点之间的是相对固定, 而 \(n_{texture}\) 是该空间上的一个线性组合, 在让 \(n_{texture}\) 与顶点建立了关系.
切线空间是一个描述顶点上法线向量的局部坐标系, 在一定程度上是一个对象坐标系,
也因此, 与对象坐标系一样, 切线空间上的对象在经过变换之后就到世界坐标系上.
我们用 \(M_{tbn}\) 来表示从切线空间到世界坐标系的变换: TBN Matrix.
TBN 分别是取自 Tangent, Bitangent 和 Normal 的首字母, 分别代表着构成切线空间的 3 个基向量.
人们 规定 面法线 \(n_{plane}\) 作为基底 Normal, 剩下工作的就是找出 Tangent 和 Bitangent.
和其它变换一样, 要找平面上方向向量变换前和变换后的数学关系即可.
变换后的好说, 三角形的 3 个顶点就是世界空间上的, 对它们进行运算就可以得到变换后的方向向量.
变换前的方向向量则需要从纹理坐标发掘, 因为几何信息里面只有它们和顶点存在某种变换关系了.
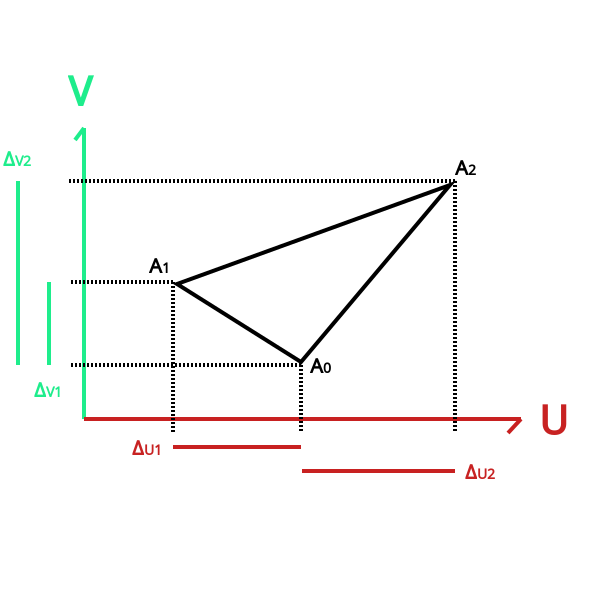
Figure 7: 三角形俯视图 - 三角形顶点与其纹理坐标的对应关系
假设现在有一个三角形 \(A_{0}A_{1}A_{2}\), 基向量 \(T = (x_{T}, y_{T}, z_{T})\) 和 \(B = (x_{B}, y_{B}, z_{B})\), 可以得出这个关系:
\(\begin{equation*}\left\{\begin{aligned} A_{1} - A_{0} &= (x_{01}, y_{01}, z_{01}) = \Delta_{U1} T + \Delta_{V1} B = \Delta_{U1}(x_{T}, y_{T}, z_{T}) + \Delta_{V1} (x_{B}, y_{B}, z_{B}) \\ A_{2} - A_{0} &= (x_{02}, y_{02}, z_{02}) = \Delta_{U2} T + \Delta_{V2} B = \Delta_{U2}(x_{T}, y_{T}, z_{T}) + \Delta_{V2} (x_{B}, y_{B}, z_{B}) \end{aligned}\right.\end{equation*}\)
\(\begin{equation*} \left(\begin{array}{c} x_{01} & y_{01} & z_{01} \\ x_{02} & y_{02} & z_{02} \end{array}\right) = \left(\begin{array}{c} \Delta_{U1} & \Delta_{V1} \\ \Delta_{U2} & \Delta_{V2} \end{array}\right) \left(\begin{array}{c} x_{T} & y_{T} & z_{T} \\ x_{B} & y_{B} & z_{B} \end{array}\right) \end{equation*}\)
\(\begin{equation*} \left(\begin{array}{c} x_{T} & y_{T} & z_{T} \\ x_{B} & y_{B} & z_{B} \end{array}\right) = \left(\begin{array}{c} \Delta_{U1} & \Delta_{V1} \\ \Delta_{U2} & \Delta_{V2} \end{array}\right)^{-1} \left(\begin{array}{c} x_{01} & y_{01} & z_{01} \\ x_{02} & y_{02} & z_{02} \end{array}\right) \end{equation*}\)
把 \(\left(\begin{array}{c} \Delta_{U1} & \Delta_{V1} \\ \Delta_{U2} & \Delta_{V2} \end{array}\right)^{-1}\) 展开后如下:
\(\begin{equation*} \left(\begin{array}{c} x_{T} & y_{T} & z_{T} \\ x_{B} & y_{B} & z_{B} \end{array}\right) = \frac{1}{\Delta_{U1}\Delta_{V2} - \Delta_{U2}\Delta_{V1}}\left(\begin{array}{c} \Delta_{V2} & -\Delta_{V1} \\ -\Delta_{U2} & \Delta_{U1} \end{array}\right) \left(\begin{array}{c} x_{01} & y_{01} & z_{01} \\ x_{02} & y_{02} & z_{02} \end{array}\right) \end{equation*}\)
这样就能求出 \(TB\) 平面了.
假如面法线是根据三角形的顶点算出, 那么计算方式是:
\(\begin{equation*} \begin{aligned} N = n_{plane} &= (x_{N}, y_{N}, z_{N}) \\ &= (A_{1} - A_{0}) \times (A_{2} - A_{0}) \\ &= (x_{01}, y_{01}, z_{01}) \times (x_{02}, y_{02}, z_{02}) \\ &= (y_{01}z_{02} - y_{02}z_{01}, x_{01}z_{02} - x_{02}z_{01}, x_{01}y_{02} - x_{02}y_{01}) \end{aligned} \end{equation*}\)
接下来对它们进行规范化, 分别得到单位向量 \(T^{'}\), \(B^{'}\) 和 \(N^{'}\), 并把组合出矩阵 \(M^{'}_{tbn}\):
\(T^{'} = \left(\frac{T}{|T|}\right)^{T} = \left( \frac{\left(\begin{array}{c}x_{T} & y_{T} & z_{T} \end{array}\right)}{\sqrt{x_{T}^{2} + y_{T}^{2} + z_{T}^{2}}} \right)^{T}\)
\(B^{'} = \left(\frac{B}{|B|}\right)^{T} = \left( \frac{\left(\begin{array}{c}x_{B} & y_{B} & z_{B} \end{array}\right)}{\sqrt{x_{B}^{2} + y_{B}^{2} + z_{B}^{2}}} \right)^{T}\)
\(N^{'} = \left(\frac{N}{|N|}\right)^{T} = \left( \frac{\left(\begin{array}{c}x_{N} & y_{N} & z_{N} \end{array}\right)}{\sqrt{x_{N}^{2} + y_{N}^{2} + z_{N}^{2}}} \right)^{T}\)
\(M^{'}_{tbn} = \left( \begin{array}{c|c} T^{'} & B^{'} & N^{'} \end{array} \right)\)
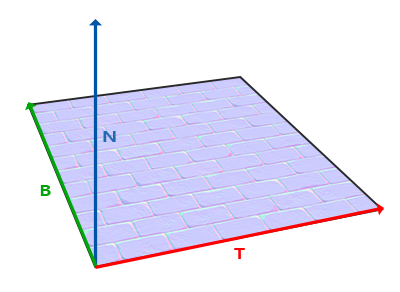
Figure 8: TBN 坐标系
然而 \(M^{'}_{tbn}\) 的基向量并不保证正交, 为了得出正交的 \(M_{tbn}\), 需要通过 格拉姆-施密特处理(Gram-Schmidt process) 让 \(M^{'}_{tbn}\) 进行正交化,
通俗点说就是让 \(T^{'}\), \(B^{'}\) 和 \(N^{'}\) 三者相互垂直. 以 \(N^{'}\) 为基准重新对齐 \(T^{'}\) 得到 \(T^{''}\) 为例: \(T^{''} = \frac{T^{'} - (T^{'} \cdot N^{'}) \times N^{'}}{|T^{'} - (T^{'} \cdot N^{'}) \times N^{'}|}\),
\(B^{'}\) 的对齐可以直接通过 \(N^{'}\) 和 \(T^{''}\) 的叉乘求出得到 \(B^{''}\): \(B^{''} = \frac{N^{'} \times T^{''}}{|N^{'} \times T^{''}|}\).
由于我们的 \(M_{tbn}\) 是从切线空间到世界坐标系的变换, 所以还需要对三个基向量进行 \(M_{model}\) 变换,
最后得出 \(M_{tbn} = \left( \begin{array}{c|c} M_{model} T^{''} & M_{model} B^{''} & M_{model} N^{'} \end{array} \right)\). 这就是目前规范的 \(M_{tbn}\) 构建方法.
可以看到 \(B^{'}\) 全程没有参与到 \(B^{''}\) 的运算过程中, 也就是说整个构建过程中可以忽略 \(B^{'}\) 向量.
另外, 这里是假设 \(M_{model}\) 的缩放变换是等比缩放, 否则 \(M_{model} N^{'}\) 要替换成 \(M_{model}^{-1} N^{'}\).
BONUS: 证明经过施密特正交化后的单位向量 \(D\) 垂直于作为基准的 \(N\)
证明如下:
假设现在有 \(T = \left(\begin{array}{c} x_{1} & y_{1} & z_{1} \end{array}\right)\) 和 \(N = \left(\begin{array}{c} x_{2} & y_{2} & z_{2} \end{array}\right)\) 两个未正交的单位向量.
根据施密特正交化进行计算, 以 \(N\) 为基准让 \(T\) 垂直于 \(N\).
\(C = T \cdot N = x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}\)
\(C \times N = \left(\begin{array}{c} (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \times x_{2} & (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \times y_{2} & (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \times z_{2} \end{array}\right)\)
最后得出经过对齐后的向量 \(D\),
\(D = T - C \times N = \left(\begin{array}{c} x_{1} - (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \times x_{2} & y_{1} - (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \times y_{2} & z_{1} - (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \times z_{2} \end{array}\right)\)
这里不需要对 \(D\) 做规范化, 是否为单位向量不影响 \(D\) 是否垂直于 \(N\), 接下来只要证明 \(D \cdot N = 0\) 即可证明 \(D\) 垂直于 \(N\).
对 \(D \cdot N\) 结果进行变换:
\(\begin{equation*} \begin{aligned} D \cdot N = & x_{1} \times x_{2} - (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \times x_{2}^{2} + y_{1} \times y_{2} \\ & - (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \times y_{2}^{2} + z_{1} \times z_{2} \\ & - (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \times z_{2}^{2} \\ = & x_{1} \times x_{2} - x_{1} \times x_{2} \times x_{2}^{2} - y_{1} \times y_{2} \times x_{2}^{2} - z_{1} \times z_{2} \times x_{2}^{2} + y_{1} \times y_{2} - x_{1} \times x_{2} \times y_{2}^{2} \\ & - y_{1} \times y_{2} \times y_{2}^{2} - z_{1} \times z_{2} \times y_{2}^{2} + z_{1} \times z_{2} - x_{1} \times x_{2} \times z_{2}^{2} - y_{1} \times y_{2} \times z_{2}^{2} - z_{1} \times z_{2} \times z_{2}^{2} \\ = & x_{1} \times x_{2} - x_{1} \times x_{2} \times (x_{2}^{2} + y_{2}^{2} + z_{2}^{2}) + y_{1} \times y_{2} \\ & - y_{1} \times y_{2} \times (x_{2}^{2} + y_{2}^{2} + z_{2}^{2}) + z_{1} \times z_{2} - z_{1} \times z_{2} \times (x_{2}^{2} + y_{2}^{2} + z_{2}^{2}) \\ = & (x_{1} \times x_{2}) \times (1 - x_{2}^{2} - y_{2}^{2} - z_{2}^{2}) + (y_{1} \times y_{2}) \times (1 - x_{2}^{2} - y_{2}^{2} - z_{2}^{2}) + (z_{1} \times z_{2}) \times (1 - x_{2}^{2} - y_{2}^{2} - z_{2}^{2}) \\ = & [1 - (x_{2}^{2} + y_{2}^{2} + z_{2}^{2})] \times (x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2}) \\ \end{aligned} \end{equation*}\)
其中 \(x_{2}^{2} + y_{2}^{2} + z_{2}^{2}\) 是向量 \(N\) 的模长的 2 次方, 因为 \(N\) 是单位向量(模长为 1), 所以 \(1 - (x_{2}^{2} + y_{2}^{2} + z_{2}^{2}) = 0\),
所以 \(D \cdot N = 0\), \(D\) 垂直于 \(N\).
这个证明同时也说明了 在进行施密特正交化前对向量做的规范化是必需的.
(PS: 准确来说只要对作为基准的向量 \(N\) 做规范化就可以了.)
因为 \(T\) 和 \(N\) 两者是不正交的, 也就是不垂直的, 所以 \(T \cdot N = x_{1} \times x_{2} + y_{1} \times y_{2} + z_{1} \times z_{2} \ne 0\).
也就是说只有 \(1 - (x_{2}^{2} + y_{2}^{2} + z_{2}^{2}) = 0\) 才能让 \(D \cdot N = 0\) 成立.
3D转化成2D图像
当求出对象的视点坐标后,就需要把 3D 场景转化为 2D 图像了,因为计算机显示器就是一个 2D 平面,这需要把 3D 投影到计算机屏幕上成为一张 2D 图片.
这一个过程经历3个步骤,
第一步 选择相机看到的内容, 因为相机是不能看到完整场景的(不可能看到无限远),
所以要先求出相机看到空间范围, 因此需要求出哪些顶点是在视野范围内的,
顶点的视点坐标的每个分量都是有范围的, 比如 \((x_e \in [l, r], y_e \in [t, b], z_e \in [n, f])\), 范围外的顶点就会被丢弃.
这个过程叫做视截体剔除(frustum culling)/裁剪(clipping),最后会看到的空间形状形成一个几何体(下面会有图片),
但由于各种变换的缘故, 没有办法写三个条件语句来判断顶点是否在范围内, 所以裁剪也是需要变换的.
如果不理解这句话是什么意思, 可以看一下这个例子:
有一个平面坐标系, 坐标系未经过任意变换时, 想让坐标 \((x, y)\) 往右移动 1 个单位就是 \((x + 1, y)\),
坐标系往逆时针方向旋转 \(45^{c}\) 之后, 想让坐标往右移动一个单位就是 \((x + \frac{\sqrt{2}}{2}, y + \frac{\sqrt{2}}{2})\).
你应该能看到同样是移动一个单位, 但是分量的变化发生了改变, 如果分量有范围, 那么范围也要遵守一样的变化,
因此, 想只靠三个条件语句做裁剪那是不太可能的.
之前几个阶段用到的顶点的坐标都是 \(\left(x, y, z, w\right)\), \(w=1\) 的这种形式, 确定顶点是否在视野内的是由根据 \(w\) 的值来决定的,
所以现在不能单纯地把 \(w\) 设定为 1,这需要经过计算,最后得到的坐标叫做裁剪坐标(clip coordinates, 也可以叫投影坐标):
\(\left(x_{clip}, y_{clip}, z_{clip}, w_{clip}\right)\)
这个步骤除了裁剪外,还会计算顶点投影后的坐标,所以这个过程也叫做投影变换(projection transformation).
到这一步为止,
Vertex Shader阶段已经结束了, 后面的两个步骤都是OpenGL内部步骤.
第二步,把看到的空间范围映射到一个"容器"中, "容器" 上的坐标被称为标准化设备坐标(normalized device coordinates, 简称 NDC).
任何超出这个"容器"的顶点都不会被渲染,这一步就是把上面计算得到的空间范围缩放到这个"容器"里面.
这个"容器"是一个立方体,使用的是左手坐标系,三轴的范围分别都是 \(\left[-1, 1\right]\).(下面会有图),
相比与其它坐标系, 标准化设备坐标系是少有的被 OpenGL 明确定义了的坐标系.
只需要进行透视除法(perspective divide)就可以把 \(\left(x_{projection}, y_{projection}, z_{projection}, w_{projection}\right)\) 转换 NDC 坐标:
\(\left(x_{ndc}, y_{ndc}, z_{ndc}\right) = \left(\frac{x_{projection}}{w_{projection}}, \frac{y_{projection}}{w_{projection}}, \frac{z_{projection}}{w_{projection}}\right)\)
不满足这个条件 \(-w_{projection} \leq x_{projection}, y_{projection}, z_{projection} \leq w_{projection}\) 的顶点都会被丢弃, 因为 \(-1 \leq x_{ndc}, y_{ndc}, z_{ndc} \leq 1\).
这个过程叫做 NDC 变换(NDC transformation).相信你已经发现 NDC 的每个分量其实就是一个比例,什么之间比例呢?
这就涉及到 NDC 的作用了,它是用来适配视口(viewport)的,
比如 NDC 的 \(x_{n}\) 分量就是裁剪坐标 \(x_{projection}\) 与视口宽度的 一半 的比例,这个比例乘以视口的尺寸就可以计算出点在视口中的实际位置.
第三步,就是把裁剪空间里面的内容适配到视口上,这一步叫视口变换(viewport transformation), NDC 是一个比例集合,
通过这个比例集合可以计算出一个顶点输出到视口上的位置,
通俗点说就是计算出这个顶点要显示在哪个像素上,如何描述像素的位置呢?
这就需要一个概念叫做窗口坐标(window coordinate)/屏幕坐标(screen coordinates)了,
我们把这个坐标系统上的所有点的集合叫做图像空间(Image Space).
屏幕坐标系就是以屏幕左上角为原点(OpenGL 传统是左下角为原点), 向右为 \(+x\), 向下为 \(+y\),一个像素为一个单位的坐标系,
假设成像窗口是一个左上角位于屏幕的 \(\left(x, y\right)\) 并且宽和高分别为 \(w\) 和 \(h\) 的矩形,
根据 NDC 可以计算出对应的屏幕坐标: \(\left(\begin{array}{c}x_{w} \\ y_{w} \\ z_{w}\end{array}\right) = \left(\begin{array}{c} \frac{w}{2} \cdot x_{ndc} + (x + \frac{w}{2}) \\ \frac{h}{2} \cdot y_{ndc} + (y + \frac{h}{2}) \\ \frac{f-n}{2} \cdot z_{ndc} + \frac{f+n}{2} \end{array}\right)\).
\(z_{w}\) 是深度值, 在许多场景发挥着非常重要的作用. 实际上 \(z_{w}\) 的计算方式并不固定, 在后面的 Depth Buffer 中会了解到.
一旦计算完后,就要把内容渲染到视口上了(也就是转化成像素),这过程叫做光栅化(raterization),这个过程不是本文的重点,以后会说.
视口变换这一步很简单,该讲的都讲完了,重点是前面两步.
到了这一步,其实整个 Primitive Assembly 环节就完成了.
从视点坐标到裁剪坐标的变换,再到标准化设备坐标.
先看一下如何选择相机看到的内容,有两种选择方案,如下,
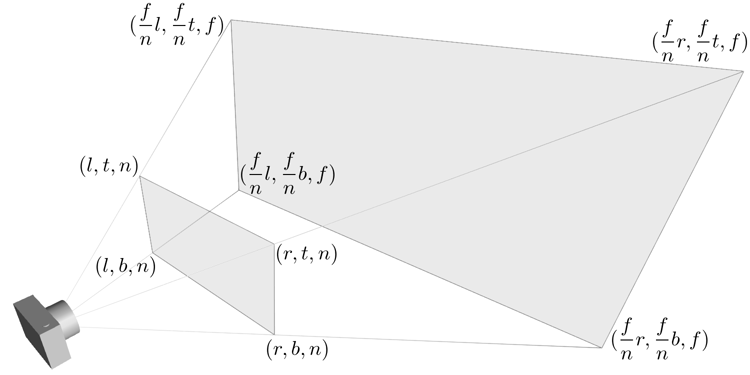
Figure 9: 透视投影(投影相机看到的内容)
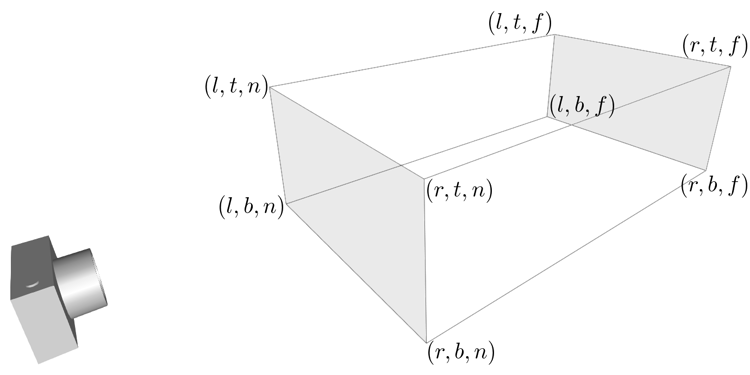
Figure 10: 正交投影(正交相机看到的内容)
图中的两个多边体分别就是眼睛能够看到的空间,选择相机的内容就是构建出这两个多边体,
这两个多边体叫做视体(view volume),第一个是截了头的锥体(frustum), 第二个是长方体.
构造这两个多边体都只需要 6 个参数, 分别是 \(l(eft)\), \(r(ight)\), \(b(ottom)\), \(t(op)\), \(n(ear)\) 以及 \(f(ar)\),
并让这 6 个参数要满足这样的关系 \(\begin{equation*} \left\{ \begin{aligned} & l < r \\ & b < t \\ & 0 < n < f\end{aligned} \right. \end{equation*}\).
(PS: 有些文章会让 \(n\) 和 \(f\) 小于 0, 无论哪种定义, 只要推导过程对了结果就是对的)
可以看到每个多边体都有两个比较深色的平面,
离相机近叫做近裁剪平面(near plane / near clipping plane),
远的叫做远裁剪平面(far plane / far clipping plane).
这两种选择方案分别叫做: 透视投影(perspective projection)以及正交投影(orthographic projection).
在 OpenGL 中,视点空间上的点会被投影到近裁剪平面上, 所以近裁剪平面也叫投影平面(projection plane).
你可能会问为什么看到的内容不是从相机位置到远处, 而是要从截头开始呢?
在学习透视投影的后就会明白 \(n = 0\) 会如何影响计算结果.
透视投影
这种投影符合人的视觉: 两条平行线会随着距离边远而慢慢靠近,最后在无限的远处进行相交(可以参考上面齐次方程里面的那张图).
这有一个信息:一个点坐标的 \(z\) 分量与它的 \(x\) 和 \(y\) 分别存在某种联系.在后面的推导中可以证明这个信息是对的.
现在找出透视投影的矩阵,首先目前已经知道的信息有:
- 计算出坐标的 \(w\) 用于之后的裁剪,再把坐标变换成标准化设备坐标系,
- 顶点会被投影到近裁剪平面上
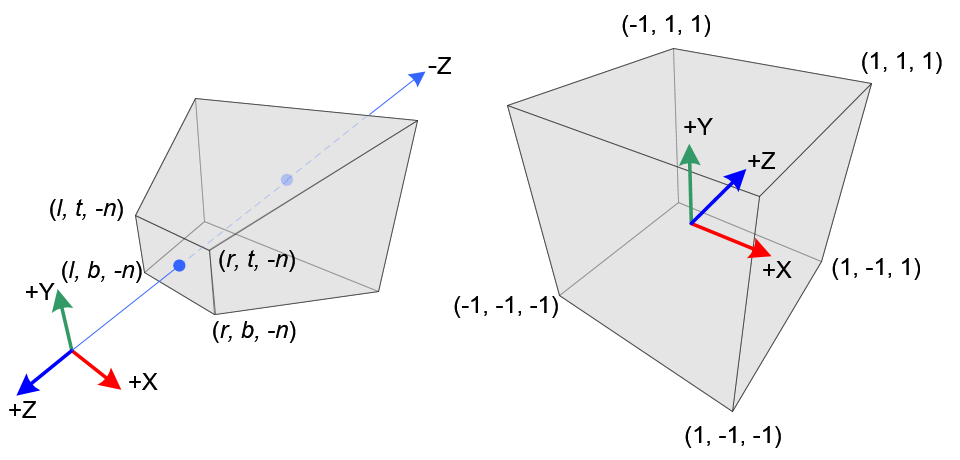
Figure 11: 透视投影2
这里第一个就是视点标系上的透视截头锥体, 是右手坐标系;
第二个是标准化设备坐标系, 是左手坐标系, 两者的 \(Z\) 轴方向是相反的.
为了方面说明推导过程, 先声明一些变量:
由于相机看向的是世界坐标系的 \(-Z\) 方向, 所以近和远裁剪平面到相机的距离 \(-n\) 和 \(-f\),
投影矩阵 \(M_{projection} = \left(\begin{array}{c} x_{l} & x_{u} & x_{f} & x \\ y_{l} & y_{u} & y_{f} & y \\ z_{l} & z_{u} & z_{f} & z \\ w_{l} & w_{u} & w_{f} & w \end{array}\right)\),
裁剪坐标 \(p_{p} = \left(\begin{array}{c} x_{p} \\ y_{p} \\ z_{p} \\ w_{p} \end{array}\right) = M_{projection}\left(\begin{array}{c}x_{e} \\ y_{e} \\ z_{e} \\ w_{e}\end{array}\right)\),
NDC 坐标 \(p_{n} = \left(\begin{array}{c}x_{n} \\ y_{n} \\ z_{n}\end{array}\right) = \left(\begin{array}{c}\frac{x_{p}}{w_{p}} \\ \frac{y_{p}}{w_{p}} \\ \frac{z_{p}}{w_{p}} \end{array}\right)\),
视点坐标 \(p_{e} = \left(\begin{array}{c} x_{e} \\ y_{e} \\ z_{e} \end{array}\right)\).
下图是一个视点空间上的点 \(p_{e}\) 如何投影到近裁剪平面的点 \(p_{p}\) 上.
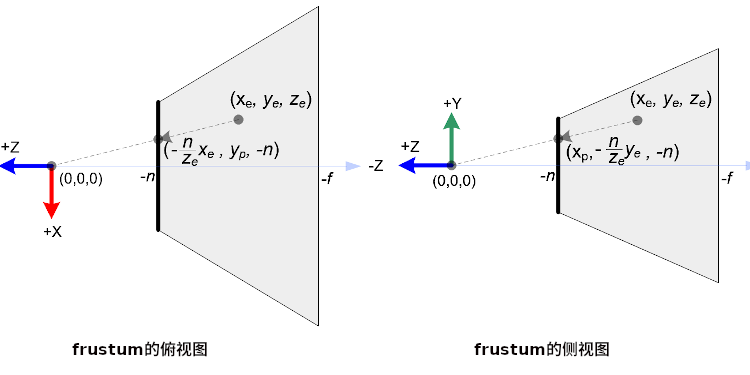
从俯视图可以看到 \(x_{e}\) 投影到 \(x_{p}\) 上,可以看到原点加上 \(p_{e}\) 配合 \(z\) 轴可以组成一个三角形,
而原点加上 \(p_{p}\) 配合 \(z\) 轴同样可组成一个三角形,并且两个三角形是相似三角形.
根据这个关系可以得到 \(\frac{x_{p}}{x_{e}} = \frac{-n}{z_{e}}\),所以 \(x_{p} = \frac{-nx_{e}}{z_{e}} = \frac{nx_{e}}{-z_{e}}\).
从侧视图也可以看出两个相似三角形, \(y_{e}\) 投影到 \(y_{p}\) 上,根据关系可以的 \(\frac{y_{p}}{y_{e}} = \frac{-n}{z_{e}}\),所以 \(y_{p} = \frac{-ny_{e}}{z_{e}} = \frac{ny_{e}}{-z_{e}}\).
注意, \(x_{p}\) 和 \(y_{p}\) 都取决于 \(z_{e}\),且成反比关系,考虑到后面还有 NDC 转换: \(\left(\begin{array}{c}x_{n} \\ y_{n} \\ z_{n}\end{array}\right) = \left(\begin{array}{c}\frac{x_{p}}{w_{p}} \\ \frac{y_{p}}{w_{p}} \\ \frac{z_{p}}{w_{p}} \end{array}\right)\),
为了方便归一化以及反转 \(z\) 轴的正负方向, 可以把 \(w_{p}\) 取为 \(-z_{e}\),
透视投影过程变成 \(\left(\begin{array}{c} x_{p} \\ y_{p} \\ z_{p} \\ w_{p} \end{array}\right) = \left(\begin{array}{c} x_{l} & x_{u} & x_{f} & x \\ y_{l} & y_{u} & y_{f} & y \\ z_{l} & z_{u} & z_{f} & z \\ 0 & 0 & -1 & 0 \end{array}\right) \left(\begin{array}{c}x_{e} \\ y_{e} \\ z_{e} \\ w_{e}\end{array}\right)\), 这样透视投影矩阵的第4行就确定了.
既然如此,那么 \(x_{p}\) 以及 \(y_{p}\) 是不是可以分别取 \(nx_{e}\) 以及 \(ny_{e}\) 了吗?
还不能这么断言, 仍然需要找到 \(p_{p}\) 到 \(p_{n}\) 之间映射关系来进行验证, 也就是找出 \(x_{p}\), \(y_{p}\) 和 \(z_{p}\) 分别到 \(x_{n}\), \(y_{n}\) 和 \(z_{n}\) 的关系:
\(\begin{equation*} \left\{ \begin{aligned} x_{p} \in \left[l, r\right] \longrightarrow x_{n} \in \left[-1, 1\right] \\ y_{p} \in \left[t, b\right] \longrightarrow y_{n} \in \left[-1, 1\right] \end{aligned} \right. \end{equation*}\)
对于 \(x_{p}\longrightarrow x_{n}\), 先假设下面函数图对应的函数为 \(x_{n} = k \cdot x_{p} + c\),
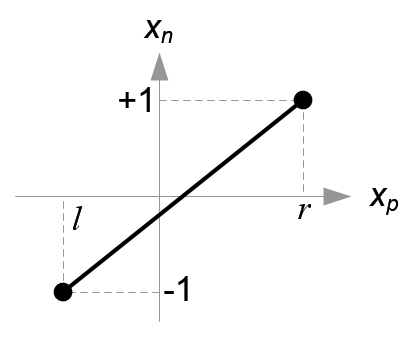
Figure 12: Mapping from \(x_{p}\) to \(x_{n}\)
\(k\) 实际上就是直线的斜率,也就是三角形的高比底边,所以 \(k = \frac{1-\left(-1\right)}{r-l} = \frac{2}{r-l}\).
最后把 \(\left(l, -1\right)\) 或者 \(\left(r, 1\right)\) 代入假设的等式中求出 \(c\), 这里就用 \(\left(r, 1\right)\) 代入,得到 \(1 = \frac{2r}{r-l} + c\), 得到
\(\begin{equation*} \begin{aligned} c &= 1 - \frac{2r}{r-l} \\ &= \frac{r-l}{r-l} - \frac{2r}{r-l} \\ &= \frac{r-l-2r}{r-l} \\ &= -\frac{r+l}{r-l}\end{aligned}\end{equation*}\),
所以 \(x_{n} = \frac{2x_{p}}{r-l} - \frac{r+l}{r-l}\).
对于 \(y\),同样先假设 先假设 \(y_{n} = k \cdot y_{p} + c\),同样的推导过程(过程就省略了),最后得出 \(y_{n} = \frac{2y_{p}}{t-b} - \frac{t+b}{t-b}\).
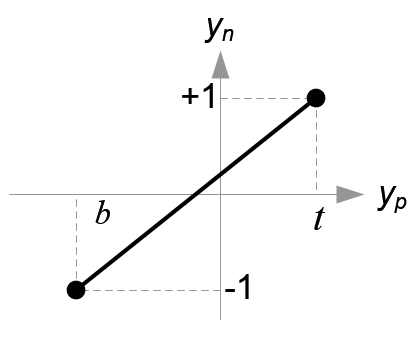
Figure 13: Mapping from \(y_{p}\) to \(y_{n}\)
然后把 \(x_{p} = \frac{nx_{e}}{-z_{e}}\) 以及 \(y_{p} = \frac{ny_{e}}{-z_{e}}\) 代入上面求得的等式中:
\(\begin{equation*}\begin{aligned} x_{n} &= \frac{2x_{p}}{r-l} - \frac{r+l}{r-l} \\ &= \frac{2 \cdot \frac{n \cdot x_{e}}{-z_{e}}}{r-l} - \frac{r+l}{r-l} \\ &= \frac{2n \cdot x_{e}}{\left(r-l\right)\left(-z_{e}\right)} - \frac{r+l}{r-l} \\ &= \frac{\frac{2n}{r-l} \cdot x_{e}}{-z_{e}} - \frac{r+l}{r-l} \\ &= \frac{\frac{2n}{r-l} \cdot x_{e}}{-z_{e}} + \frac{\frac{r+l}{r-l} \cdot z_{e}}{-z_{e}} \\ &= \frac{ \frac{2n}{r-l} \cdot x_{e} + \frac{r+l}{r-l} \cdot z_{e} } {-z_{e}} \end{aligned} \end{equation*}\) 以及 \(\begin{equation*}\begin{aligned} y_{n} &= \frac{2y_{p}}{t-b} - \frac{t+b}{t-b} \\ &= \frac{2 \cdot \frac{n \cdot y_{e}}{-z_{e}}}{t-b} - \frac{t+b}{t-b} \\ &= \frac{2n \cdot y_{e}}{\left(t-b\right)\left(-z_{e}\right)} - \frac{t+b}{t-b} \\ &= \frac{\frac{2n}{t-b} \cdot y_{e}}{-z_{e}} - \frac{t+b}{t-b} \\ &= \frac{\frac{2n}{t-b} \cdot y_{e}}{-z_{e}} + \frac{\frac{t+b}{t-b} \cdot z_{e}}{-z_{e}} \\ &= \frac{ \frac{2n}{t-b} \cdot y_{e} + \frac{t+b}{t-b} \cdot z_{e}}{-z_{e}} \end{aligned} \end{equation*}\).
从转换到 NDC 逆推回去可以得到 \(x_{p} = \frac{2n}{r-l} \cdot x_{e} + \frac{r+l}{r-l} \cdot z_{e}\) 以及 \(y_{p} = \frac{2n}{t-b} \cdot y_{e} + \frac{t+b}{t-b} \cdot z_{e}\),因此 \(M_{projection} = \left(\begin{array}{c} \frac{2n}{r-l} & 0 & \frac{r+l}{r-l} & 0 \\ 0 & \frac{2n}{t-b} & \frac{t+b}{t-b} & 0 \\ z_{l} & z_{u} & z_{f} & z \\ 0 & 0 & -1 & 0 \end{array}\right)\),
这样一来,透视投影的矩阵就只剩下第 3 行,也就是 \(z_{p}\longrightarrow z_{n}\) 轴的关系了,这个不像前面那样,再整理一下当前已知信息:
- 投影的点都是在近裁剪平面上的,
OpenGL需要它能够用于裁剪以及深度测试(depth test) 的唯一 \(z_{p}\) 值,并且还能够反投影(unproject/inverse transform),- \(x_{p}\) 以及 \(y_{p}\) 取决于 \(z_{e}\)
根据第三条信息可以知道 \(z_{p}\) 不取决于 \(x_{e}\) 以及 \(y_{e}\), 所以可以得到 \(M_{projection} = \left(\begin{array}{c} \frac{2n}{r-l} & 0 & \frac{r+l}{r-l} & 0 \\ 0 & \frac{2n}{t-b} & \frac{t+b}{t-b} & 0 \\ 0 & 0 & z_{f} & z \\ 0 & 0 & -1 & 0 \end{array}\right)\).
再根据 \(\left(\begin{array}{c}x_{n} \\ y_{n} \\ z_{n}\end{array}\right) = \left(\begin{array}{c}\frac{x_{p}}{w_{p}} \\ \frac{y_{p}}{w_{p}} \\ \frac{z_{p}}{w_{p}} \end{array}\right)\), 可以得到 \(z_{n} = \frac{z_{p}}{w_{p}} = \frac{z_{f} \cdot z_{e} + z \cdot w_{e}}{-z_{e}}\), 因为在视点空间上, \(w_{e} = 1\), 所以 \(z_{n} = \frac{z_{f} \cdot z_{e} + z}{-z_{e}}\).
还是根据变换到 NDC 的过程: \(\left[-n,-f\right] \longrightarrow \left[-1, 1\right]\),把 \(\left(-n, -1\right)\) 以及 \(\left(-f, 1\right)\) 代入到上面的等式中, 得到:
\(\begin{equation*}\left\{\begin{aligned} -1 = \frac{-z_{f} \cdot n + z}{n} \\ 1 = \frac{-z_{f} \cdot f + z}{f} \end{aligned} \right. \longrightarrow \left\{\begin{aligned} -n = -z_{f} \cdot n + z \\ f = -z_{f} \cdot f + z \end{aligned} \right. \end{equation*}\)
把其中一个等式改写成以 \(z\) 作为因变量的等式, 这里采用第一个: \(z = z_{f} \cdot n - n\),
再把这个等式代入另外一个等式中, 得到:
\(f = -z_{f} \cdot f + z_{f} \cdot n - n \longrightarrow f + n = -\left(f - n\right)z_{f} \longrightarrow z_{f} = -\frac{f+n}{f-n}\)
把 \(z_{f}\) 再代入回第一个等式中, 得到:
\(\frac{f+n}{f-n} \cdot n + z = -n \longrightarrow z = -n - \frac{f+n}{f-n} \cdot n = -\frac{2fn}{f-n}\), 所以 \(z_{n} = \frac{-\frac{f+n}{f-n}z_{e} - \frac{2fn}{f-n}}{-z_{e}}\),
最后透视投影矩阵 \(M_{projection} = \left(\begin{array}{c} \frac{2n}{r-l} & 0 & \frac{r+l}{r-l} & 0 \\ 0 & \frac{2n}{t-b} & \frac{t+b}{t-b} & 0 \\ 0 & 0 & -\frac{f+n}{f-n} & -\frac{2fn}{f-n} \\ 0 & 0 & -1 & 0 \end{array}\right)\).
透视投影 - Depth Buffer
参考资料:
LearnOpenGL - Depth TestingHow does openGL come to the formula F_depth and and is this the window viewport transformationHow to go from device coordinates back to worldspace in OpenGL (with explanation)
Depth Buffer 又叫 Depth Texture, Z-Buffer.
它是一个数组, 储存了要输出到屏幕上的像素深度(depth): 从像素所对应的顶点(vertex)到相机的距离.
因此, 这个数组的长度为 "窗口宽度(\(width_{screen}\))" 乘以 "窗口高度(\(height_{screen}\))".
OpenGL 会把 NDC 的 \(z_{n}\) 分量从 \([-1, 1]\) 映射到 \([0, 1]\) 作为深度值 \(d = (z_{n} + 1) \div 2\) 储存在 depth buffer 中.
(PS: 其实 glDepthRange(a, b) 可以改变这个映射范围到 \([a, b]\): \(a + (a - b) \times d\), 但是为了简化下面的计算推导, 我选择最简单的范围: \([0, 1]\).)
如果有多个坐标点 \((x_{n}, y_{n}, z_{n})\) 之间存在相同 \(x_{n}\) 分量和相同 \(y_{n}\) 分量, 但 \(z_{n}\) 分量不同的情况,
OpenGL 根据其对应的 \(d\) 选出最靠近相机的坐标点进行绘制,
同时 OpenGL 会把这个坐标点的所对应的深度值 \(d\) 储存到 Depth Buffer 数组索引 \(y_{n} \times width_{screen} + x_{n}\) 的位置上.
透视投影所产生的 \(d\) 被称为非线性深度(non-linear depth), 我会通过公式变换来进一步说明为什么.
在这个变换会演示如何通过视点坐标的 \(z\) 分量 \(z_{e}\) 快速计算出顶点的非线性深度:
\(\begin{equation*} \begin{aligned} d &= (z_{n} + 1) \div 2 \\ &= \left( \frac{-\frac{f+n}{f-n}z_{e} - \frac{2fn}{f-n}}{-z_{e}} + 1 \right) \div 2 \\ &= \left( \frac{\frac{-z_{e}(f+n) - 2fn}{f-n}}{-z_{e}} + 1 \right) \div 2 \\ &= \left( \frac{-z_{e}(f+n) - 2fn}{-z_{e}(f-n)} + 1 \right) \div 2 \\ &= \left( \frac{-z_{e}(f+n) - 2fn}{-z_{e}(f-n)} + \frac{-z_{e}(f-n)}{-z_{e}(f-n)} \right) \div 2 \\ &= \frac{2\times -z_{e}f - 2fn}{-z_{e}(f-n)} \div 2 \\ &= \frac{-z_{e}f - fn}{-z_{e}(f-n)} \\ &= \frac{f(z_{e} + n)}{z_{e}(f-n)} \\ &= \frac{f}{f - n} + \frac{1}{z_{e}} \frac{n}{f - n} && \text{这里就可以看出 }d\text{与 }\frac{1}{z_{e}}\text{ 成线性关系}\\ &= \frac{n + z_{e}}{z_{e}n} \times \frac{fn}{f-n} \\ &= \frac{n + z_{e}}{z_{e}n} \div \frac{f-n}{fn} \\ &= (\frac{1}{z_{e}} + \frac{1}{n}) \div (\frac{1}{n} - \frac{1}{f}) \\ &= \frac{\frac{1}{z_{e}} + \frac{1}{n}}{\frac{1}{n} - \frac{1}{f}} \\ &= \frac{-\frac{1}{z_{e}} - \frac{1}{n}}{\frac{1}{f} - \frac{1}{n}} \end{aligned} \end{equation*}\)
如变换结果所示, \(d\) 不仅不与 \(z_{e}\) 成线性关系, 反而与 \(\frac{1}{z_{e}}\) 成线性关系, 这就是为什么 \(d\) 被称为非线性深度.
有时候, 我们需要根据深度值 \(d\) 来获得像素对应的视点坐标的 \(z_{e}\) 分量来编写 Fragment Shader 来实现一些效果,
所以有必要掌握从深度值 \(d\) 反推 \(z_{e}\) 的计算方法.
在拿到深度值 \(d\) 后首先就把它转换成 NDC 的分量 \(z_{n} = 2 \times d - 1\), 然后问题就变成"如何从 NDC 坐标计算出视点坐标".
简单来说有两种方法, 两者其实本质上是一样的, 都是通过 \(M_{projection}\) 的逆矩阵 \(M_{projection}^{-1}\) 配合 NDC 坐标 \(p_{n}\) 来逆运算出结果.
我们知道 NDC 坐标 \(p_{n}\) 是裁剪坐标 \(p_{p}\) 进行透视除法后的结果, 但它并没有裁剪坐标 \(p_{p}\) 的 \(w_{p}\) 分量,
所以通过 \(p_{n}\) 直接计算出 \(p_{p}\) 需要绕一下路:
方法一:
在透视投影的推导过程, 我们获得如下关系:
\(p_{p} = M_{projection}p_{e}\)
\(p^{'}_{n} = \left(p_{n} | 1\right)^{T} = \frac{p_{p}}{w_{p}} = \left(\begin{array}{c} \frac{x_{p}}{w_{p}} \\ \frac{y_{p}}{w_{p}} \\ \frac{z_{p}}{w_{p}} \\ \frac{w_{p}}{w_{p}} = 1 \end{array}\right)\), (不用担心 \(p_n\) 的 \(x_{n}\) 和 \(y_{n}\) 分量, 实际开发中会拿得到的, 这里忽略它们)
\(p_{p} = w_{p}p^{'}_{n}\)
\(p_{e} = M_{projection}^{-1}p_{p} = w_{p}M_{projection}^{-1}p^{'}_{n}\)
正如上面的关系所示, 只要求出 \(w_{p}\) 就可以求出 \(p_{e}\), 但是从 \(p_{n}\) 和 \(p^{'}_{n}\) 的定义来看, \(w_{p}\) 的信息是缺失的.
幸运的是, 我们知道视点坐标的 \(w\) 分量是 1, 所以可得 \(w_{e} = 1\), 有了这条关系求 \(w_{p}\) 就很简单了:
我们用 \((M_{projection}^{-1}p^{'}_{n})_{w}\) 表示获取运算结果中的 \(w\) 分量, 可以得到: \(w_{e} = w_{p}(M_{projection}^{-1}p^{'}_{n})_{w} = 1\).
这样就可以把 \(w_{p}\) 的信息补上了: \(w_{p} = \frac{1}{(M_{projection}^{-1}p^{'}_{n})_{w}}\).
现在离求得 \(z_{e}\) 只差最后一步了:
令 \(p^{'}_{e} = M_{projection}^{-1}p^{'}_{n}\), 可得 \(p_{e} = w_{p}p^{'}_{e}\), 进而得到 \(w_{p} = \frac{1}{(M_{projection}^{-1}p^{'}_{n})_{w}} = \frac{1}{(p^{'}_{e})_{w}}\),
最终, 得到 \(p_{e} = \frac{p^{'}_{e}}{(p^{'}_{e})_w} = \frac{M^{-1}_{projection} p^{'}_{n}}{ (M^{-1}_{projection} p^{'}_{n})_w } = \left(\begin{array}{c} \frac{(p^{'}_{e})_x}{(p^{'}_{e})_w} \\ \frac{(p^{'}_{e})_y}{(p^{'}_{e})_w} \\ \frac{(p^{'}_{e})_z}{(p^{'}_{e})_w} \\ \frac{(p^{'}_{e})_w}{(p^{'}_{e})_w} = 1 \end{array}\right)\).
方法二:
这个方法比起第一种方法就简单很多了, 直接通过 \(M_{projection}\) 的第三行反推:
\(z_{n} = \frac{z_{p}}{w_{p}} = \frac{-\frac{f+n}{f-n}z_{e} - \frac{2fn}{f-n}}{-z_{e}} = \frac{f+n}{f-n} + \frac{2fn}{f-n} \times \frac{1}{z_{e}}\)
\(z_{n}(f - n) = (f + n) + \frac{2fn}{z_{e}}\)
\(z_{n}(f - n) - (f + n) = \frac{2fn}{z_{e}}\)
\(z_{e} = \frac{2nf}{z_{n}(f - n) - (f + n)}\)
有些效果需要使用线性深度(linear depth), 比如物体阴影(shadow map), 雾效(fog),
相比非线性深度反映物体与相机在视觉中的距离, 线性深度更能反映物体与相机之间在世界中的距离,
这也是为什么这些效果会采用线性深度. 所谓线性深度的定义如下:
\(d_{linear} = \frac{-z_{e} - n}{f - n}\), \(d_{linear} \in [0, 1]\)
这就是掌握把透视投影的深度 \(d\) 还原成 \(z_{e}\) 的方法的其中一个理由: 计算出线性深度 \(d_{linear}\).
线性的 depth buffer 原本就在正交投影中产生, 在学习正交投影矩阵后就可以知道 \(d_{linear}\) 的定义怎么来了.
透视投影 - FOV (Field of View)
很多图形库的设定投影相机的函数需要视场角(fov), 裁剪平面的宽高比(aspect)以及近裁剪平面(n)以及远裁剪平面(f)作为输入参数.
以 three.js 为例,并非用前面提到6个参数设定相机,不过两者其实是有联系的,毕竟内部还是使用6参数来设定相机的.
\(fov\) 是相机看到的视野范围的角度,从上面的图片 透视投影 可以看出视线会形成一个角度,那个角度就是 \(fov\),
再观察 frustum的俯视图 以及 frustum 的侧视图 可以知道有两个 \(fov\),分别是水平方向的 fov 以及垂直方向的 fov.
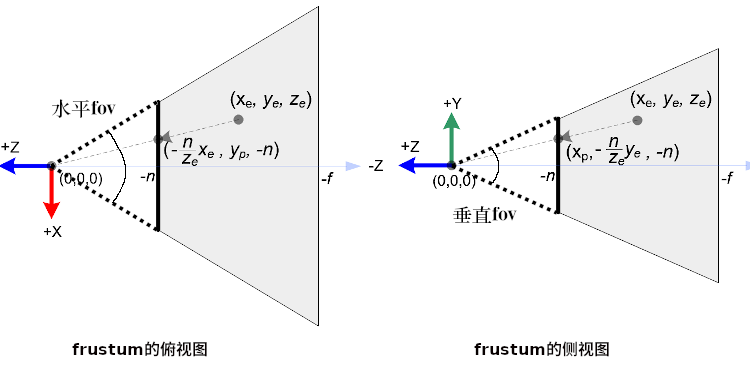
以 three.js 为例子, 它就是使用的水平方向 \(fov\), 假设现在水平方向 \(fov\) 是 \(\theta\),
需要根据 \(fov\) 计算出6参数,其中 \(n\) 和 \(f\) 都知道了,可以直接根据 \(n\) 和 \(\theta\) 计算出 \(l\) 和 \(r\).
根据 frustum的俯视图 可以看出 \(\frac{\frac{r-l}{2}}{n} = \frac{r-l}{2n} = \tan\frac{\theta}{2}\),然后 \(r-l = 2n\tan\frac{\theta}{2}\).
\(r-l\) 就是近裁剪平面的宽,根据裁剪平面的宽高比 \(aspect\) 可以得出高 \(t-b = \frac{r-l}{aspect}\),
最后以宽和高各自的中心点划分, 也就是 \(\begin{equation*}\left\{\begin{aligned}|r| = |l| = \frac{r-l}{2} \\ |t| = |b| = \frac{t-b}{2}\end{aligned} \right.\end{equation*}\),
这样就可以得出 \(l(eft)\), \(r(ight)\), \(t(op)\) 以及 \(b(ottom)\) 4个参数了,
(需要保证满足关系 \(\begin{equation*}\left\{\begin{aligned}r > l \\ t > b\end{aligned}\right.\end{equation*}\)),
加上一开始给出的 \(n(ear)\) 和 \(f(ar)\) 就凑齐了6个参数来构建截头锥体.
\(fov\) 还可以用来实现视觉上的缩放, 根据关系: \(r - l = 2n \tan \frac{\theta}{2}\), 当 \(fov\)(\(\theta\)) 缩小, \(n\) 不变, 那么 \(r - l\) 变小,
所以视觉内容就变少, 同时画面输出的大小不变, 造成内容"密度"降低, 形成画面放大的效果; 同理, 反过来就是缩小.
\(fov\) 的改变还可以用来实现希区柯克镜头(Hitchcock shot/Dolly Zoom): 移动相机来拉近/拉远与拍摄对象的距离,
同时对镜头进行变焦, 来保持拍摄对象在视野中的大小.
简单来说就是 \(r - l\) 的大小固定, 对 \(n\) 和 \(\theta\) 进行变化.
现实中, 镜头的焦距越长(也就是 \(n\) 越大), \(fov\) 就越小; 焦距越短, \(fov\) 越大.
在实际拍摄电影中, 手动调整焦距和相机与拍摄对象之间的距离, 是很难保证拍摄对象在视觉上保持固定大小的.
因为手动调整是不可能有计算机的精确度的, 所以如果要模拟现实中的效果,
可以适当模拟一下"偏差", 也就是 \(r - l\) 可以产生允许范围内的变化.
/** * Dolly zoom from https://medium.com/@gianluca.lomarco/from-perspective-to-orthographic-camera-in-three-js-with-dolly-zoom-vertigo-effect-96de89c3a07b */ const finalFOV = 0.5 const initialPos = camera.position.clone() const fovTan = Math.tan(MathUtils.degToRad(fov / 2)) const RATIO = initialPos.length() * fovTan function updateCamera(progress) { const newFOV = MathUtils.lerp(fov, finalFOV, progress) const newFovTan = Math.tan(MathUtils.degToRad(newFOV / 2)) const d = RATIO / newFovTan camera.fov = newFOV camera.position.normalize().multiplyScalar(d) camera.updateProjectionMatrix() }
正交投影
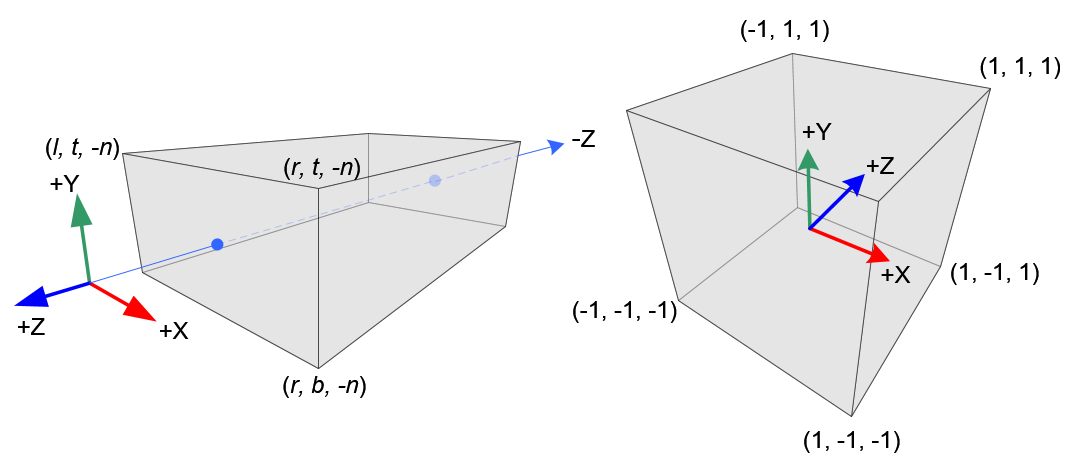
Figure 14: 正交投影2
正交投影比透视投影要简单的多, 这种投影不符合人的视觉, 两条平行不会在远处慢慢靠近最后相交,
视体就是一个由6参数计算得到的长方体, 视点坐标到投影坐标的变换就是一组简单的线性关系:
\(\begin{equation*} \left\{ \begin{aligned} x_{p} &= k_x \cdot x_{e} + c_x \\ y_{p} &= k_y \cdot y_{e} + c_y \\ z_{p} &= k_z \cdot z_{e} + c_z \end{aligned} \right. \end{equation*}\)
而且知道长方体的尺寸, \(k_x\), \(k_y\), \(k_z\) 甚至可以完成归一化, 使得 \(-1 \le x_p, y_p, z_p \le 1\), 直接完成视点到 NDC 的转换:
\(\begin{equation*} \left\{ \begin{aligned} x_{n} &= k_x \cdot x_{e} + c_x \\ y_{n} &= k_y \cdot y_{e} + c_y \\ z_{n} &= k_z \cdot z_{e} + c_z \end{aligned} \right. \end{equation*}\)
比如参考图片上正交投影中 \(x_{e}\) 到 \(x_{n}\) 的关系图, 我们需要把 \([l, r]\) 映射到 \([-1, 1]\) 中,
当 \(x_e = l\) 时 \(x_n = -1\), 当 \(x_e = r\) 时, \(x_n = 1\), 所以 \(\begin{cases} 1 = k_x \cdot r + c_x \\ -1 = k_x \cdot l + c_x \end{cases}\),
两者相减可以得出 \(2 = k_x (r - l) \rightarrow k_x = \frac{2}{r-l}\), 把 \(k_y\) 代入回去求得 \(c = -\frac{r + l}{r - l}\);
同理可得 \(k_y = \frac{2}{t - b}\), \(c_y = -\frac{t + b}{t - b}\);
\(k_z\) 就有点特殊, 因为是从 \([-n, -f]\) 映射到 \([-1, 1]\), 所以 \(\begin{cases} 1 = k_{z} \cdot -f + c_z \\ -1 = k_{z} \cdot -n + c_z \end{cases}\),
经过计算得到 \(k_z = \frac{2}{n - f} = - \frac{2}{f - n}\) 以及 \(c_z = \frac{n + f}{n - f} = -\frac{f + n}{f - n}\),
最终关系为 \(\begin{equation*} \left\{ \begin{aligned} x_{n} &= \frac{2}{r-l} \cdot x_{e} - \frac{r+l}{r-l} \\ y_{n} &= \frac{2}{t-b} \cdot y_{e} - \frac{t+b}{t-b} \\ z_{n} &= -\frac{2}{f - n} \cdot z_{e} - \frac{f+n}{f - n} \end{aligned} \right. \end{equation*}\), 所以 \(M_{projection} = \left(\begin{array}{c} \frac{2}{r-l} & 0 & 0 & -\frac{r+l}{r-l} \\ 0 & \frac{2n}{t-b} & 0 & -\frac{t+b}{t-b} \\ 0 & 0 & -\frac{2}{f-n} & -\frac{f+n}{f-n} \\ 0 & 0 & 0 & 1 \end{array}\right)\).
观察该矩阵可以发现 \(x_{n}\) 和 \(y_{n}\) 的计算过程不涉及 \(n\) 和 \(z_{p}\), 因此, 正交投影不会有近大远小的视觉效果.
因为这个特性, 正交投影非常适合在 3D 游戏中绘制 2D UI, 3D 的内容用透视投影成像, 2D UI 用正交投影成像,
取消深度测试, 把 2D UI 覆盖在 3D 内容上, 在这个过程中, 3D 与 2D 两者最终的成像比例是一致,
可以想象成把两张图片叠在一起, 以 three.js 为例,
const width = 16 const height = 9 const near = 1 const far = 100 const aspect = width / height // 获得 3D 成像的比例, 第一个重点 const persCam = new THREE.PerspectiveCamera(75, aspect, near, far) const orthoFrustumHeight = 5 // 随便指定正交视椎体高度, 但要为整数 第二个重点 const left = orthoFrustumHeight * aspect / -2 const right = orthoFrustumHeight * aspect / 2 const top = orthoFrustumHeight / 2 const bottom = -orthoFrustumHeight / 2 // 根据 aspect 计算 left / right / top / bottom, 使得最终成像的比例和 3D 成像的比例一致, 第三个重点 const orthoCam = new THREE.OrthographicCamera(left, right, top, bottom, near, far)
其中 left/right 是 2D UI 画布在水平方向的范围, top/bottom 则是在垂直方向上的范围,
这个时候可以把正交相机看作一个画板, 它的坐标系是水平范围在 [left, right], 垂直范围在 [bottom, top], 原点在正中心.
在绘制 UI 元素时需要根据这个坐标系来对元素进行定位.
接下来
这篇笔记涵盖了大部分 OpenGL 中所发生基底变换以及如何构建它们所对应的矩阵,
写这篇笔记是因为:
- 网上大部分参考资料太多太零散, 时间一久就很难找出来, 需要整理到一块方便日后查询;
- 大部分文章的推导过程不够完整, 缺少一些中间过程, 有必要进行补全方便理解.
这里面很多内容都会对每个想入门 Shader 编程的人有所帮助, 编写 Shader 不可避免的需要用到数学运算.
这篇笔记大部分章节的数学内容都是针对 vertex shader 阶段, 只有少数几个章节针对 fragment shader 阶段, 还有另外小部分是渲染管线内部的计算.
Vertex shader 是计算顶点的变换后的位置, fragment shader 则是计算出像素(pixels)的颜色, fragment Shader 输入的对象是片元(fragments),
这篇文章的内容可以让你从零开始编写 vertex shader 实现出 OpenGL 默认的 vertex shader 的行为,
然而, 并不足以让你从零开始编写出 fragment shader 实现出默认行为, 这要求先了解如何完整实现整个渲染流程.
接下来我不会像这篇笔记一样为渲染这块编写笔记, 因为:
- 是渲染这话题有点大, 有点超出我的精力, 目前这篇笔记已经耗费了我大量精力了;
- 是目前存在一些非常不错的教程或书籍, 没必要重复造轮子, 搞不好容易给网上添垃圾.
个人推荐 Computer Graphics from Scratch, 这本书配有代码(可运行在浏览器上), 介绍了光追和光栅化两种渲染方法.
(这本书还有中文实体书, 价格也不贵.)
这一节写于 2024 年, 但笔记最初是写于 2020 年.
之所以写得这么晚是因为 "Computer Graphics from Scratch" 成书于 2021 年,
本人也是由于事情繁忙断断续续的才把这么书读完, 并且用
C语言实现了里面的内容, 结果一眨眼就到 2023 年底了.
光栅化就是 OpenGL 所采用的渲染方法, 但书本上的实现和 OpenGL 的具体实现有点不一样,
正是由于这一些的不同, 你才能看清其本质部分, OpenGL 的流程只是其中一种实现方式, 每个图形库都会在一些具体细节上面显得不一样.
在阅读时可以 尝试 把这篇笔记的内容和书本内容联系起来, 这样会让你对光栅化渲染有更深一层的理解.
之后最多写一下关于这本书的阅读笔记, 把其中的一些值得理解的内容写下来.
在读或者读完这本书之后可以看一下我这一篇笔记:(Shader编程自救指南)学习基础的 Shader 编程知识, 然后用 GLSL 来实现前面所学到的知识.