关于使用C语言开发的那些事
Table of Contents
注意, 看这篇笔记时请务必先学习 x86 汇编, 因为 C 代码会被编译成汇编,
只有学习了汇编你才能具体得看到 C 语言的内存管理模型, 知道程序是如何产生的, 是什么样的.
这篇文章是我在上手使用 C 语言开发时遇到了一些疑问而突发奇想写出来的,
这些疑问包括为什么要写头文件, 如何自己发布库文件, 如何发布项目代码, 如何构建项目等等.
相信很多初学者和我有同样的疑问, 很多 C 语言的书记都不会收录这些内容, 这也是情有可原的,
毕竟 C 语言的工具链比较复杂, 可选择范围太广, 不太可能单独介绍的.
我这篇笔记都是主要是围绕 GNU 提供的工具链进行的: GNU C Compiler, GNU Binutils 和 GNU Autotools,
以及 Kitware 提供的 CMAKE.
本文不是关于 C 语言教学的, 只是单纯的工具上手教学, 看之后保证你掌握大概用法, 以及如何查工具文档.
最后提一句, 这篇文章里面所有操作都是在 Linux 上完成的.
UPDATED AT 2023/5/9
本人发现了一本可以替代这篇笔记的书 "21st Century C, 2nd Edition",
这本书对于从汇编转 C 的新手来说是非常不错的实践参考, 并且内容详略得当.
这篇文章也有些书本上没有的内容, 虽然存在意义不太大了, 但笔记还是得保留下来.
GNU Binutils
学 C 语言时除了掌握 GCC 以及相关的构建工具意外, 还需要掌握一些工具用于使用/调试/分析二进制文件.
在 Linux 上只要安装 binutils 就可以得到这个工具集了, 比如 Ubuntu 上只要运行 sudo apt-get install binutils 就可以了.
这篇笔记通篇都使用了这些工具, 很多工具的用法只会简单介绍一下, 更多的内容请自行阅读 man page.
关于使用 GCC 的须知事项
预处理阶段的一些细节
我们从一个简单的例子出发:
// eatc.c #include <stdio.h> int main(int argc, char **argv) { printf("Eat something!\n"); return 0; }
在得到源代码后, 就是编译生成程序了: gcc eatc.c -o eatc, 这命令会发生以下过程,
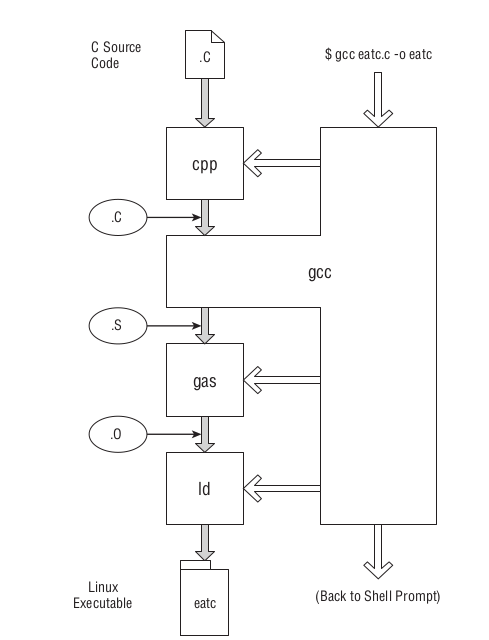
Figure 1: GCC编译C语言并生成程序
我们这里的目标是研究预处理(CPP)这个阶段发生了什么.
当我们在编译时加多一个 --save-temps 选项:
gcc --save-temps eatc.c -o eatc
可以得到 eatc.i 和 eatc.s 两个额外的文件, 这个选项是编译过程中生成的中间文件给保留下来,
其中 eatc.s 是源代码对应汇编码, 这块已经能够单独出一门课程了, 这里不深入研究.
我们的目标是 eatc.i 文件, 这个文件其实就是对应 CPP 阶段生成的 .c 文件,
对比 eatc.c 而言, eatc.i 在 GCC 眼中 eatc.i 才是纯 C 文件 (pure c file).
我们可以简单地把预处理理解为源代码的文本处理:
- 移除
.c文件里面的注释; - 使用预处理器的指令生成文本, 或者定义宏(Macro);
把宏替换成对应的文本;
预处理指令都是
#开头的, 这个例子只使用了#include(也可以写成# include这样子) 一个预处理指令, 它的作用只是把指定的文件内容复制插入到它的位置上而已, 这点可以从eatc.i和stdio.h进行内容对比一探究竟.#include <stdio.h>就是先从系统预设的路径查找stdio.h, 这个路径在 Linux 上通常都是/usr/include这个目录下,我本人电脑上
stdio.h的完整路径就是/usr/include/stdio.h.接下来我们对比一下
eatc.i和stdio.h两者头部的内容差别,eatc.i的头部:# 0 "eatc.c" # 0 "<built-in>" # 0 "<command-line>" # 1 "/usr/include/stdc-predef.h" 1 3 4 # 0 "<command-line>" 2 # 1 "eatc.c" # 1 "/usr/include/stdio.h" 1 3 4 # 27 "/usr/include/stdio.h" 3 4 # 1 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 1 3 4 # 33 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 3 4 ...
/usr/include/stdio.h的头部:/* Define ISO C stdio on top of C++ iostreams. Copyright (C) 1991-2022 Free Software Foundation, Inc. This file is part of the GNU C Library. The GNU C Library is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version. The GNU C Library is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details. You should have received a copy of the GNU Lesser General Public License along with the GNU C Library; if not, see <https://www.gnu.org/licenses/>. */ /* * ISO C99 Standard: 7.19 Input/output <stdio.h> */ #ifndef _STDIO_H #define _STDIO_H 1 #define __GLIBC_INTERNAL_STARTING_HEADER_IMPLEMENTATION #include <bits/libc-header-start.h> ...
可以看到除了被移除的注释和一些陌生的指令以外, 感觉上是差不多的,
这点可以从
eati.i的# 1 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 1 3 4这种注释看出来.如果觉得这不太好看出来的话, 你可以把例子改成如下:
// eatc.c #include <stdio.h> int main(int argc, char **argv) { printf("Eat something!\n"); return 0; #include "right-bracket"
// right-bracket }
再次检查
eatc.i文件的尾部:# 4 "hello-world.c" int main(int argc, char **argv) { printf("Eat something!\n"); return 0; # 1 "right-bracket" 1 } # 8 "hello-world.c" 2
多了一行处理日志的注释
# 1 "right-bracket" 1, 并且我们的程序也能通过编译以及运行.
接下来解释一下什么是宏, 我们简单地把宏看作一个可以用来生成文本的 文本模板,
我认为, 要理解这个概念就需要以带参数的宏来作为起点例子.
我们把上面的
eatc.c改写成用参数宏来生成函数main的定义:// eatc.c #include <stdio.h> #define MAIN_CLOSURE(...) int main (int argc, char **argv ) { __VA_ARGS__ } MAIN_CLOSURE ( printf("Eat something!\n"); return 0; )
我们可以对比一下前后两次编译得
eatc.i里的函数main长什么样子的,第一次生成的:
# 4 "hello-world.c" int main(int argc, char **argv) { printf("Eat something!\n"); return 0; }
第二次生成的:
# 6 "hello-world.c" int main (int argc, char **argv ) { printf("Eat something!\n"); return 0; }
可以看到两者的格式上虽然有些不太一样, 但定义可以说是一模一样的.
第二个版本中
eatc.c的宏MAIN_CLOSURE就是把int main (int argc, char **argv ) { __VA_ARGS__ }这一部分文本作为一个模板,在预编译阶段里面就往模板里面的
__VA_ARGS__这个位置插入文本, 而这些被插入的文本就是作为MAIN_CLOUSRE参数传入的,这里例子里被插入的文本就是
printf("Eat something!\n"); return 0;.MAIN_CLOSURE还不是一个普通的参数宏, 它是一个可变参数宏,__VA_ARGS__就表示那个可变参数....宏也是可以不带参数的, 初学者很容易看见
#define NUM 1这种简单的宏, 我之所以不以简单的例子来开始, 是因为很多初学者都以为这种简单宏看作常量的定义,然而把宏改成
#define NUM 3 - 2, 再带着这种想法去使用NUM时就导致程序发生意想不到的bug.int res = NUM * 4;
在两个不同的宏定义下, 预处理得到的结果是不一样的:
int res = 1 * 4;
int res = 3 - 2 * 4;
导致结果不一样的原因正是是初学者都以为宏是普通的变量定义, 而不是文本生成.
不过哪怕一开始强调是文本生成, 初学者也不一定能理解, 因此先解释清楚文本生成是什么一个概念才是最重要的,
而本人认为解释这一概念最应该先找一个能够区分得了变量定义和文本生成两者差别的例子, 那么带参数的宏不就最能体现吗?
至于那些说函数和带参数的宏也很像的人, 我想说的是, 难道函数能够做到像
MAIN_CLOSURE玩弄源代码那种事情吗?还需要声明一点的是, 预处理器本身体不属于 C 语言的定义里头的, 它是属于编译器, 因此你用别的编译器是, 所支持的预处指令/宏定义都是不同的,
详情参考 GCC的 CPP 文档.
最后再注意的一点是, 定义宏时需要严格遵守格式:
#define SIMPLE_MACRO_NAME text或#define ARG_MACRO_NAME(arg1, arg2, ...) text这种格式,因为宏本身就是一个文本模板,
SIMPLE_MACRO_NAME和text之间要用一个空格隔开, 多余的空格算到text里面,而带参数的宏
ARG_MACRO_NAME和它后面的参数列表之间是不能有空格的, 否者就是SIMPLE_MACRO_NAME那种情况了;此外,
text是只能占一行的, 如果你觉得一行不好写实在要换行, 可以告诉编译器: "我现在手动换行, 你后面要把它拼成一行",我以改写前面的
MAIN_CLOSURE作为例子:#define MAIN_CLOSURE(...) int main (int argc, char **argv ) { \ __VA_ARGS__ \ }
宏定义时的一些惯例
do {} while(0)定义: https://stackoverflow.com/a/2687595((void)0)占位符: https://stackoverflow.com/a/2198975宏的相关资料
头文件以及库文件的一些细节
通常情况下, 头文件(.h)的内容都是一些宏/变量的定义以及变量/函数的声明(declarations),
.c 文件用来存放对应头文件里变量/函数对应的实现(implementation), 或者说定义(definitions).
事实上你完全把整个项目的源代码可以在一个文本文件里面, 声明和定义可以不分开, 都能够编译出一个能运行的程序.
在 GCC 眼中, 源码文件的 .h 和 .c 后缀都是没有意义上不同的, 它不会知道 .h 就是主要用于提供声明, .c 提供定义.
那么为什么开发人员需要这种区分呢? 这就要从一个最简单且完整的 C 程序说起:
// simple-c.c // 定义函数 int func ( int a, int b ) { return a + b; } // 程序入口 int main( int argc, char **argv ) { func( 1, 2 ); // 使用定义的函数 return 0; }
或者是:
// simple-c.c // 程序入口 int main( int argc, char **argv ) { func( 1, 2 ); // 使用定义的函数 return 0; } // 定义函数 int func ( int a, int b ) { return a + b; }
这两者实际上都能编译通过并运行程序, 学过其它语言的人可能觉得这没什么问题, 但是对于编译器则不一定了,
本人用的是 GCC 11.2.0 默认的 C 标准 ISO C17, 在编译时, 后者比起前者会多出一个警告:
simple-c.c: In function ‘main’: simple-c.c:4:3: warning: implicit declaration of function ‘func’ [-Wimplicit-function-declaration] 4 | func(1, 2); | ^~~~
这是因为 GCC 是逐行编译导致的, 它每处理一条句时都会对遇到里面的变量/函数名字查找到其对应的信息,
检测这个变量是什么类型, 这个函数接收什么样的参数以及返回什么样的值, 编译器需要根据这些信息估算要使用的内存空间以及评估你的程序是否存在什么问题.
但是在第二种的情况下编译时, GCC 是先编译 main, 在 main 里面找 func 的定义, 这个时候编译器还不清楚 func 长什么样,
于是它只能根据上下文"猜"出 func 的样子.
解决这个警告很简单:
// simple-c.c // 在调用func前为其进行声明 int func( int, int ); // 程序入口 int main( int argc, char **argv ) { func( 1, 2 ); // 使用定义的函数 return 0; } // 定义函数 int func ( int a, int b ) { return a + b; }
我们姑且先把这一次的版本叫做最终版吧, 第一个版本叫做初版.
可以看到最终版里面的声明只提供函数的名字, 其参数类型以及返回值, 这些信息是必须的, 后续的定义需要和这些关键信息要保持一致;
而参数名则是可选信息, 即便是写了, 也不需要和定义里头的参数名一样, 但为了代码可读性还是建议写上.
我们可以反过来只提供声明不提供定义, 看看编译会发生什么?
这里以最终版为例, 把 func 注释掉后会得到一个链接器报的错误:
/usr/bin/ld: /tmp/ccxdFKZ5.o: in function `main': simple-c.c:(.text+0x1e): undefined reference to `func' collect2: error: ld returned 1 exit status
在 C 语言里面, 如果声明前面没有加任何 extern 和 static 关键字, 就默认 extern 关键字,
extern 就是告诉编译器模块引用的定义可能由别的模块提供;
static 关键字则告诉编译器模块内的定义不能被其它模块引用.
由于声明默认是 extern 关键字, 因此, extern 的一般是用来暗示引用其它模块中的定义, 没有实质作用.
回到例子中, 当不在源代码里面提供 func 的定义时, 编译器就会认为 func 的定义会在别的地方,
等编译完了就交给链接器在链接时去找 func 的定义, 由于没有找到对应的定义, 于似乎它报错了.
解决这个问题除了把注释解除掉外, 还可以在使用 GCC 编译时让它链接到一个提供定义的二进制文件, 这种提供定义的二进制文件就是人们口中的库.
库分动态链接库(dynamic link library/shared link library)和静态链接库(static link library),
在 Linux 上静态链接库的后缀是 .a(rchive), 动态链接库的后缀是 .s(hared)o(bject).
链接动态链接库的叫做动态链接, 而把多个二进制文件链接为一体的链接方式就叫静态链接, 静态链接不一定非得使用静态库的,
动态链接得到的程序会在运行前寻找动态库并且加载, 如果找不到动态库就运行不起来;
静态链接得到的程序本身就是完整的, 因此是可以直接运行的, 然而静态链接生成的程序本体比动态链接的要大.
我们基于前面最终版的代码拆分一下用于后续演示两种链接:
// simple-c.c extern int func( int, int ); int main(int argc, char **argv) { func(1, 2); return 0; }
// simple-c-func.c int func ( int a, int b ) { return a + b; }
静态链接 有两种方法:
静态链接-1
gcc -o simple-c simple-c.c simple-c-func.c
这种方法会把中间生成若干个
.o的目标文件, 然后链接器再它们链接起来得到一个程序, 这个过程其实并未使用到静态库.这条命令等价于以下:
gcc -c simple-c-func.c gcc -c simple-c.c gcc -o simple-c simple-c.o simple-c-func.o
静态链接-2
gcc -c -o simple-c-func.o simple-c-fun.c ar rcs libsimple-c-func.a simple-c-func.o gcc -o simple-c simple-c.c -lsimple-c-func -L.
这里的
-lsimple-c-func就是让simple-c和simple-c-func.a进行链接,GCC的-l选项就是用来指定要链接的链接库名;-L指定在哪个路径下找链接库, 如果库在系统默认位置上, 那么不需要该选项指定.
动态链接 如下:
gcc -shared simple-c-func.c -o libsimple-c-func.so gcc -o simple-c simple-c.c -lsimple-c-func -L. -Xlinker -rpath -Xlinker .
需要注意这里用上了
GCC的-Xlinker选项来给ld传入-rpath .,由于编译得到的程序的文件格式是
ELF, 并且我们这个库并非在系统搜索的路径里面,因此我们需要告诉
ld该链接生成的程序在 运行时 需要从自身当前位置查找libsimple-c-func.so,如果
libsimple-c-func.so是位于ld默认的库查找路径上, 那么最后的编译命令可以写成:gcc -shared simple-c-func.c -o libsimple-c-func.so gcc -o simple-c simple-c.c -lsimple-c-func
这里有一个地方值得思考一下, 动态和静态两种链接除了生成库的方式不同以外, 在生成编译程序的命令上都是一样的,
如果
ld默认的库查找路径上同时存在一个库的动静态两个版本的库,ld又是如何选择的呢?在
GCC man page里面可以看到-l选项说明里面有这么一段描述:Static libraries are archives of object files, and have file names like liblibrary.a. Some targets also support shared libraries, which typically have names like liblibrary.so. If both static and shared libraries are found, the linker gives preference to linking with the shared library unless the -static option is used.
可以看到默认情况下是默认链接动态库, 而这个
-l选项是直接传给链接器的, 所以链接器也是这么处理的.GCC启动时会调用一个名叫 collect2 功能, 这个功能调用ld来生成一张符号表用于查找定义以及进行链接, 它就是一个链接器的封装.可以在编译时给
GCC添加一个-v选项来看看GCC给ld传了什么参数,collect2接受的参数就是ld的参数.
还有另外一个地方值得思考, 现在我们的
simple-c-func已经是一个库了, 也就是说可以用在其它程序的源代码上了.但这有一个问题, 每次用到别的程序上时, 我们都要在调用了函数
func的源代码里写上int func(int, int);这么一句,万一
simple-c-func提供了不止func一个函数呢, 岂不是要写很多个声明吗?这就是头文件存在的意义了: 把所有对应定义的声明写到一个头文件里, 在调用这些定义之前先
#include该头文件.我们都知道
#include本质上就是复制文本, 所以#include头文件这操作很好理解.因此, 上面的最终版代码可以拆开成三份来发布:
// simple-c.c #include "simple-c-func.h" int main(int argc, char **argv) { func(1, 2); return 0; }
// simple-c-func.h #ifndef SIMPLE_C_FUNC_H #define SIMPLE_C_FUNC_H int func( int, int ); #endif
// simple-c-func.c int func ( int a, int b ) { return a + b; }
然而只发布源代码的话, 拿到代码的人就不太方便使用了, 一般要提供构建工具的配置文件,构建脚本以及构建说明,
其中构建说明会描述项目依赖哪些第三方库以及构建步骤, 置文件和脚本通常都是和构建工具配合使用.
接下来会介绍构建方式, 但在讨论这个话题之前, 我们先回顾一下上个例子
eatc, 它调用了printf函数,从代码上看, 它貌似是来源于
stdio库的, 并且链接时是从系统路径上查找库的, 如果是这么想的话就不太对了.你没办法在系统路径上找到
libstdio.a或者libstdio.so的文件, 你可以ldd命令看一个可执行程序或者动态链接库链接了哪些动态链接库,我们对
ldd eatc之后可以看到以下内容:linux-vdso.so.1 (0x00007fff5cba3000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f2fcd67b000) /lib64/ld-linux-x86-64.so.2 (0x00007f2fcd8c3000)
这里引用了一个叫做
libc.so.6的动态链接库, 而printf的实现就是它提供的,libc就是C库, 而这个C库是由 GNU实现的,我们可以使用
nm来查看它的符号表:nm -Dg /lib/x86_64-linux-gnu/libc.so.6
你可以在里面找到
printf的符号信息:... 0000000000060770 T printf@@GLIBC_2.2.5 ...
当然它也有静态链接库版本, 和
libc.so.6位于同一个目录下, 名字叫做libc.a,同样也可以用
nm来列出静态链接库的符号表:nm -s /lib/x86_64-linux-gnu/libc.a
我们都知道
.a文件就是一个由多个.o文件组合而成的集合包, 可以使用一下命令看看里面有哪些.o文件:ar t /lib/x86_64-linux-gnu/libc.a
按照前面的说法个, 在静态链接中
#include "simple-c-func"对应一个simple-c-func.o或者simple-c-func.a的话,那么
libc.a是否包含一个stdio.o的文件, 并且由它提供printf函数呢?通过以下命令来查找每个
.o文件提供的了哪些符号:nm -s /lib/x86_64-linux-gnu/libc.a
我们配合
grep命令可以查找出关于printf符号的描述:nm -s /lib/x86_64-linux-gnu/libc.a | grep '^printf\s'然而我们猜错了, 在结果里面可以看到这一部分:
printf in printf.o nm: sysdep.o: no symbols nm: sigvec.o: no symbols
是不是有点意外, 虽然
#include <stdio.h>但printf是printf.o提供的.(看了一眼
glibc的源代码好像stdio是有使用到printf的, 我也不太确定).如果有兴趣的话, 可以使用以下命令把
printf.o提取出来:ar x /lib/x86_64-linux-gnu/libc.a printf.o --output .
构建工具之 CMake
在构建工具这一块, C/C++ 相对于其它语言来说有很多选择, 什么 make, CMake, automake 等等, 都能用来构建项目.
最早的构建工具应该是 make, 使用 make 需要先掌握 Makefile 的编写, make 会根据 Makefile 里面的规则对项目进行构建,
比如说前面的 simple-c 的动态链接构成的步骤用一个 Makefile 解决:
simple-c: simple-c.c simple-c-func.so gcc -o simple-c simple-c.c -lsimple-c-func -L. -Xlinker -rpath -Xlinker . simple-c-func.so: simple-c-func.c gcc -shared simple-c-func.c -o libsimple-c-func.so
(注意, 这里的缩进是一定要用制表符 tab 而不是空格 space, 否则语法不对).
接着执行 make 命令就会执行构建.
像这种简单的项目手写 Makefile 还是很方便的, 但等到项目复杂度上来了, 编写复杂度也会随之上去, 如果还要考虑平台移植问题, 还有可能需要为别的平台写多一份 Makefile.
在 1991 年的时候, 有个名为 David J. MacKenzie 的程序员厌倦了为 20 个系统(*nix 平台)单独写 Makefile 的任务, 因为每个操作系统上的编译器/链接器/头文件/库文件的路径不一定相同,
于是他写了一个叫做 configure 的脚本来根据系统生成 Makefile, 只要执行 ./configure && make 就能开始构建.
后来 GNU 把这套流程标准化了, 推出了自己的构建系统(GNU build system): 使用一套工具去生成 configure 脚本, 再执行 ./configure && make.
(有些开源项目不一定有 configure 脚本的, 这种项目一般会给你准备好 Makefile 文件.)
这里有一篇关于 GNU 构建系统的入门介绍(中文翻译) 这里就不介绍了.
其实有还有很多类似的构建系统, 相比专注于 *nix 系统的 GNU 构建系统, 能够做跨平台构建的 CMake 是一个很不错的选择,
在 *nix 上能够和 GNU 构建系统那样最终生成 Makefile;
在 Windows 上能够像 Visual Studio 构建系统那样最终生成 sln 文件.
在 *nix 上虽然有各种各样的构建工具帮助你生成 Makefile, 但作为开发人员还是要对它有一定的了解的, 这里有个不错教程: Makefile 指南(en) (英文不好可以看它的中文翻译).
跟着教程走一边基本上就 okay 了.
构建工具之 Docker
Unix 系统之所以适合用于开发 C 程序是因为它能够把库的头文件和二进制文件做好分类, 并且自动设置好环境变量提供访问.
开发的程序会直接通过这些环境变量来找到依赖库, 对于 C 语言来说, 系统本身就是一个依赖管理工具.
但这也会出现一种情况: 一个系统上有多个程序同时依赖于同一个库, 但要求版本却不统一.
传统的方法是给不同版本的库命不同的名, 通常是库名加版本号: libname.so.[version], 然后在编译链接时指定对应版本的库.
但这种方法不方便对库进行管理, 也增加手动操作的情况. 后来有一家公司想到了把系统轻量化后打包到容器中, 把容器当作程序运行在真正的系统上,
这么一来, 容器与真正的系统就形成环境隔离. 开发的程序只要能在容器上进行开发和运行,
部署时就无需担心真系统的环境是否满足程序要求. 这项技术就是 Docker.
到目前为此 C 语言不像 Rust/JavaScript 那样每个项目都有自己的的依赖管理, 因此 Docker 在一定程度上可以解决这个问题.
Docker 还是有一点点上手难度的, 不仅要求会写 shell 和 Dockerfile, 还要求对操作系统有一些了解.
这里以 Docker 构建运行 glslViewer 为例子, 作为应用部署的代表.
其实我很早之前就有写过两篇关于
Docker文章, 定位更偏入门:
首先构建目录如下:
CWD: ~/path/to/glslViewerDocker $ tree -L 1 . ├── docker-entrypoint.sh # 容器启动时的脚本 ├── Dockerfile # 镜像构建文件 ├── glslViewer # 程序的源代码 ├── image-tag.txt # 配置镜像名 ├── startup.sh # 用于启动容器 └── volumes.txt # 配置目录挂载, 格式为 /dir/in/host:/dir/in/docker, 一行一个配置
Dockerfile:
# 选择 ubuntu:22.04 作为基础镜像
FROM ubuntu:22.04
# DEBIAN_FRONTEND 是 Debian 安装程序用于设置用户界面类型的引导参数, noninteractive 意味着自动化安装, 无需人工干预
ENV DEBIAN_FRONTEND=noninteractive
# 安装 glslViewer 在 Ubuntu 上的依赖
RUN set -eux \
&& apt-get update \
&& apt-get -yq upgrade \
&& apt-get -yq install --no-install-recommends \
git build-essential cmake xorg-dev libglu1-mesa-dev libncurses5-dev libncursesw5-dev \
&& exit 0
RUN set -eux \
&& apt-get -yq install --no-install-recommends \
ffmpeg libavcodec-dev libavcodec-extra libavfilter-dev libavfilter-extra libavdevice-dev libavformat-dev libavutil-dev libswscale-dev libv4l-dev libjpeg-dev libpng-dev libtiff-dev \
&& exit 0
RUN set -eux \
&& apt-get -yq install --no-install-recommends \
xvfb \
&& exit 0
RUN set -eux \
&& apt-get -yq clean \
&& exit 0
RUN mkdir -p /app
ENV SRC_ROOT=/app/glslViewer
ENV SRC_BUILD=${SRC_ROOT}/build
# 把 glslViewer 的源代码复制到镜像里面
ADD ./glslViewer $SRC_ROOT
# 把容器入口脚本复制到容器里面
ADD ./docker-entrypoint.sh /bin/
# 保证脚本可执行
RUN chmod +x /bin/docker-entrypoint.sh
# 做构建准备, 需要参考项目的构建说明
RUN mkdir $SRC_BUILD
WORKDIR $SRC_BUILD
RUN cmake ..
RUN make
# 在启动容器时, 会自动执行 ENTRYPOINT 的命令
ENTRYPOINT [ "/bin/docker-entrypoint.sh" ]
容器入口脚本, 用来启动 glslViewer.
#!/bin/bash # docker-entrypoint.sh exec /app/glslViewer/build/glslViewer "$@"
在文件都准备好后便可以构建镜像了.
# 构建容器 cd /path/to/dir sudo docker build . -t $(cat image-tag.txt)
构建完毕后就可以启动容器了, 启动容器也是需要一定操作的,
Docker 通常用来运行 CLI 程序, 而 glslViewer 是一个 GUI 程序,
网络上这方面的资料比重稍微低一点, 遇到问题不太好解决,
这也是我选择 glslViewer 作为例子的原因: 相当有代表性,
# 修改 X server 的访问控制 xhost +local:docker # 允许 Docker 与 X server 通信, 后面会介绍什么是 X server # 启动容器的命令 sudo docker run \ --rm \ # 容器停止时删除容器 -it \ # -it 以交互形式运行容器 -e DISPLAY=$DISPLAY \ # 设置容器的 DISPLAY 环境变量为主机的 DISPLAY 环境, 尝试把容器画面输出到主机上 --network=host \ # 设置容器与主机共享同一个网络, 两者的端口共享, 只有这样容器的画面才可以输出到主机上 -v /dir/in/host:/dir/in/docker \ # 把主机的目录挂在到容器上, 让容器上的 glslViewer 可以在 /dir/in/docker 中查找文件 -w /dir/in/docker \ # 设置容器的工作路径 glslViewer-img \ # 容器的镜像 shader.frag # glslViewer 在工作路径上读取的 shader 文件, 即 /dir/in/docker/shader.frag
如果不想容器和主机共享网络, 可以把 --network-host 替换成挂载项: -v /tmp/.X11-unix:/tmp/.X11-unix.
/tmp/.X11-unix 属于 UNIX 域套接字(Unix Domain Socket), 用在同一机器内程序之间的本地通信,
它是 X server 与 X clients (即遵守 X server 协议的程序)通信的其中一种方式, 也可以用通过 TCP 和内存进行通行.
为了理解为什么这么配置能够显示容器里程序的 GUI, 接下来介绍一下 X server 这个东西:
X clients 先通过解析环境变量 DISPLAY 后得知要在哪个屏幕(screen)上绘制自己的 GUI,
把解析结果和绘制命令发送到 X server, X server 在接收到绘制命令后把绘制结果输出到对应的屏幕上.
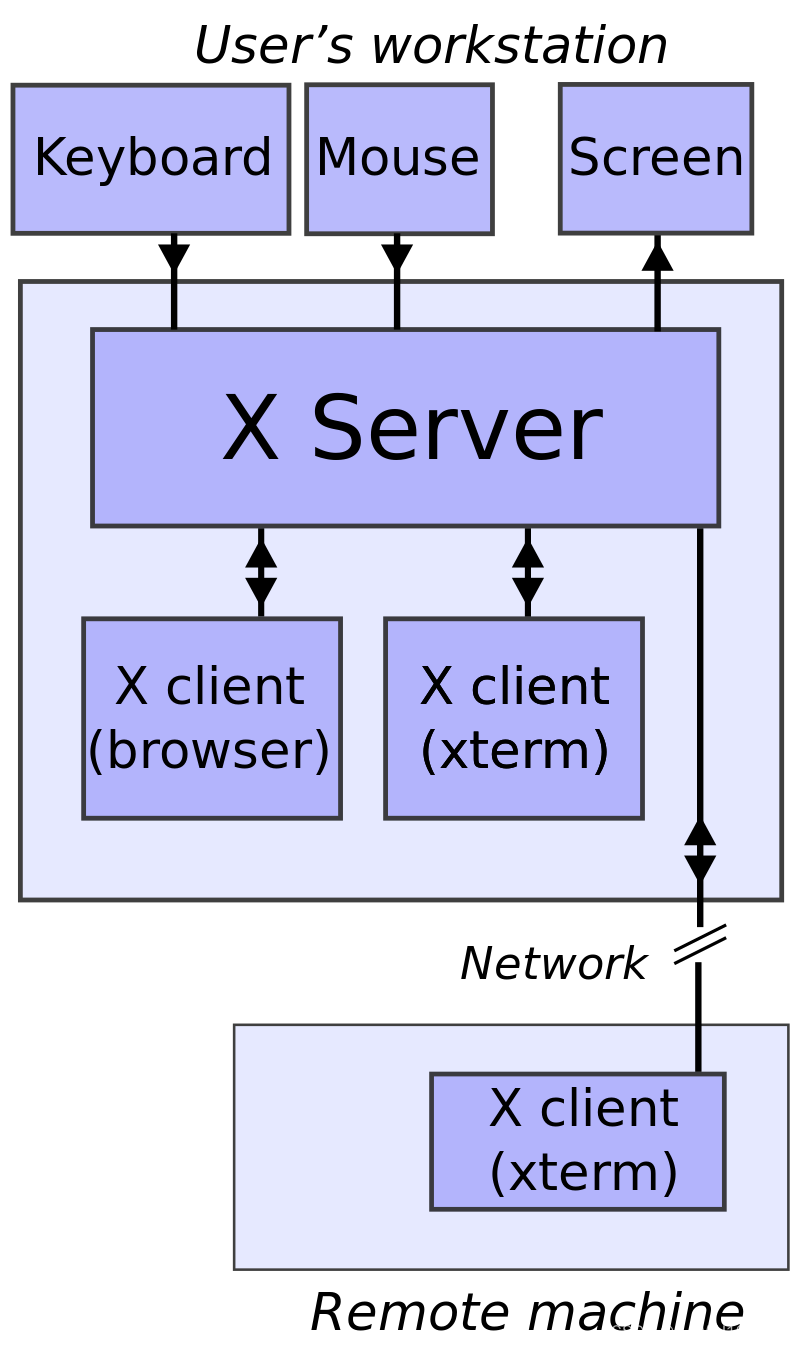
Figure 2: X Server and X Clients
其中, 一台电脑上可以运行多个 X servers, 一个 X servers 可以管理多个 screen,
一个 screen 可以对应单个或多个物理显示器, 多个物理显示器合成一个逻辑 screen.
回到容器启动上, 以同样的路径把主机上的该套接字挂载到容器上,
使得容器上的 X clients 可以直接与主机的 X server 进行通信,
这样主机上就能使用到容器上 X clients 的 GUI. --network=host 本质上也一样, 只是通信手段不太一样.
上面的启动命令太长了, 启动频繁的话会很麻烦, 所以写了一个脚本进行封装:
#!/bin/bash # startup.sh: 启动容器的命令封装 mapfile -t lines < volumes.txt printf -v volumes " -v %s" "${lines[@]}" image_tag=$(cat image-tag.txt) docker run --rm -it -e DISPLAY=$DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix \ $volumes $image_tag "$@"
以上就是使用 Docker 部署应用的情况了, 那么开发和编译呢? 这个更简单, 项目结构和构建目录保持一致,
只是 glslViewer 目录要换成自己的程序代码, 不过现在就假设我们是 glslViewer 的开发者吧.
镜像构建方面, 只要构建一个安装了依赖的镜像即可.
Dockerfile:
# 选择 ubuntu:22.04 作为基础镜像
FROM ubuntu:22.04
# DEBIAN_FRONTEND 是 Debian 安装程序用于设置用户界面类型的引导参数, noninteractive 意味着自动化安装, 无需人工干预
ENV DEBIAN_FRONTEND=noninteractive
# 安装 glslViewer 在 Ubuntu 上的依赖
RUN set -eux \
&& apt-get update \
&& apt-get -yq upgrade \
&& apt-get -yq install --no-install-recommends \
git build-essential cmake xorg-dev libglu1-mesa-dev libncurses5-dev libncursesw5-dev \
&& exit 0
RUN set -eux \
&& apt-get -yq install --no-install-recommends \
ffmpeg libavcodec-dev libavcodec-extra libavfilter-dev libavfilter-extra libavdevice-dev libavformat-dev libavutil-dev libswscale-dev libv4l-dev libjpeg-dev libpng-dev libtiff-dev \
&& exit 0
RUN set -eux \
&& apt-get -yq install --no-install-recommends \
xvfb \
&& exit 0
RUN set -eux \
&& apt-get -yq clean \
&& exit 0
ADD ./docker-entrypoint.sh /bin/
RUN chmod +x /bin/docker-entrypoint.sh
ENTRYPOINT [ "/bin/docker-entrypoint.sh" ]
这么做是因为开发中的代码需要经常更新, 所以不应该把源代码复制进镜像, 否则每次更新代码都要构建一边镜像,
正确方法是在启动容器时把代码挂载到容器上, 再进入容器里对代码进行编译.
如果不想手动的话, 可以修改 docker-entrypoint.sh 实现每次启动容器时会自动编译运行程序.
#!/bin/bash # docker-entrypoint.sh # 假设容器的源代码挂载路径为 /src/glslViewer SRC_BUILD=/src/glslViewer/build if [[ ! -d $SRC_BUILD ]]; then mkdir $SRC_BUILD fi cd $SRC_BUILD cmake .. make exec ${SRC_BUILD}/glslViewer "$@"
官方文档上关于挂载和执行 ENTRYPOINT 的顺序有间接暗示: 挂载先于执行 ENTRYPOINT,
docker run 命令会先根据镜像创建容器再运行容器, 挂载是发生在容器创建阶段,
执行 ENTRYPOINT 是发生在容器运行阶段, 所以才能在启动容器时挂载代码并成功编译运行,
在部署应用的情况中也可以采取源码挂载方案, 这样开发和部署就能共用一套构建方案,
正常情况下部署时只应发布二进制文件, 源代码不应该被包含进容器中.
最后透露一些容器管理方法, 以下方法可以批量停止容器和删除容器:
sudo docker ps -a -q | sudo xargs docker stop sudo docker ps -a -q | sudo xargs docker rm
镜像也可以通过类似的命令进行批量管理:
sudo docker images -a -q | sudo xargs docker rmi
内存检测工具
C 并不是一门内存安全型编程语言, 因此在使用 C 开发时最好使用一些工具来检测是否有内存问题.
这里推荐两个工具: Valgrind 以及 ASan.
其中 Valigrind 是 *nix 类系统独占的, 想要快速上手 Valgrind 就得理解它提供的错误信息(实际上默认情况下是 Memcheck 提供的), 关于这点可以看官方文档.
ASan 已经集成到 GCC 里面了, 只要在编译的时候添加上 -fsanitize=address 选项就能对代码进行打桩, 在运行程序的时候会提示潜在的内存问题, 具体用法可以看这里.
Valgrind 比 ASan 更加准确, 但是速度也比较慢, 精确度和速度得看自己取舍了.
交叉编译 (cross compilation)
所谓交叉编译是在一个平台上为另外一个平台编译得到可执行代码, 我们把前者叫做编译平台, 后者叫做目标平台.
这里的平台可以是操作系统(operating system), 也可以是机器架构(architecture).
编译平台本身是运行不了目标平台上的可执行程序的.
比如说在 x86_64 Linux 上编译 x86_64 Windows 的程序, 但 x86_64 Linux 并不能运行这个程序.
和交叉编译相对应的就叫做本地编译 (native compilation), 平台上编译的程序可以在本平台上跑.
如果一个平台无法或不方便进行本地编译, 那么就需要交叉编译了.
进行交叉编译需要使用对应的工具链来完成, 具体可以参考以下链接:
http://retroshare.sourceforge.net/wiki/index.php/Ubuntu_cross_compilation_for_Windows
https://cmake.org/cmake/help/book/mastering-cmake/chapter/Cross%20Compiling%20With%20CMake.html
关于 C 语言
C 语言的语法主要分两种 K&R C (Kernighan and Ritchie) 和 ANSI C.
K&R C 语法出现在 1978 年发行 "The C Programming Language" 的第一版中.
由于早期的 C 语言是和 Lisp 一样, 有着各种各样的方言, 每门方言的语法都不太一样, 于是人们就对 C 语言的语法进行规范化,
而 Kernighan 和 Ritchie 也参与其中.
这场运动的结果就是在 1989 年诞生出 ANSI C 语法, 终结了其它 C 方言的发展并且自身还在不断发展.
同时 ISO 组织把 ANSI C 加入 ISO 的大家庭里面成为 ISO C, ANSI C 和 ISO C 的差别只在于格式和排版,
因此对于开发者来说是一样的.
有一些老书籍以及其配套代码和老项目在使用 K&R C 的语法, 如果有阅读需求的话则需要了解一下 K&R C 的一些独特语法.
K&R C 的版本号叫 C78, 而第一版的 ANSI C 版本号叫做 C89, 后面的数字代表它们的发布时间, 后面的版本号也是这个规律.
读懂 C 的声明语法
指针
很多人都说 C 语言的指针很难, 个人认为他们每个人说的难可能实际上都不是指同一个东西.
首先我认为难是因为这两个原因中的任意一个或者全部: 指针的声明难以阅读; 不了解程序的内存管理, 不知道指针就是内存地址.
第一个问题在前面的读懂 C 的声明语法就有答案了,
第二个问题这就需要你去了解汇编语言了, 只有了解 C 源码编译成汇编时指针是什么样的, 才能掌握指针的用法.
指针是 C 这类语言的内存管理之道, 哪怕是深谙用法的老练开发人员也很难确保不会因疏忽导致出现内存安全问题.
新手最常见的疏忽就是使用 malloc 在堆上申请了内存区域却忘记使用 free 进行释放, C++ 里面有 RAII 来解决这个问题,
malloc会在成功申请空间后返回空间地址, 失败的时候返回null指针 (也就是NULL).根据 ISO-IEC 9899 的
C standard, 7.20.3.2/2可以得知free(NULL)也是没有问题的.因此, 在
free时不需要对malloc返回的地址做额外判断.
然而这也没有完全杜绝内存安全问题, 这是因为出现安全问题的原因很多.
通常开发人员会使用一写工具提示哪里出了内存安全问题, 在 Linux/Unix 环境上(Windows 有 WSL)可以使用 Valgrind 来进行检测.
使用的方法很简单, 在编译的时候开启调试信息生成, 比如要对前面的 simple-c 进行检测, 那么就需要这么编译:
simple-c: simple-c.c simple-c-func.so gcc -g -o simple-c simple-c.c -lsimple-c-func -L. -Xlinker -rpath -Xlinker . simple-c-func.so: simple-c-func.c gcc -g -shared simple-c-func.c -o libsimple-c-func.so
每个编译命令都加载 -g 选项, 否者 Valgrind 就会提示你的源代码的问题在第几行,
最好在加上 -O0 (Letter "O" and Digit Zero) 选项取消优化来保证调试信息达到最精确, 但其实默认优化 -O1 在大部分情况下也够用.
之后就是根据 Valgrind 的信息来修正程序错误了, 因此掌握 Valgrind 的关键是理解其错误信息的含义.
最后, 个人建议任何人都应该仔细看一遍 Valgrind 的上手教程, 特别是 Caveats 部分.
泛型指针
在声明或定义指针变量时, 开发人员都要告诉编译器指针指向的内存区域上储存什么类型的数据.
比如, int *ptr;, 就是告诉编译器, 变量 ptr 储存了一块内存区域的地址, 而这块内存区域就是用来储存整数的;
char *ptr; 所指向的内存区域则是用来储存字符的.
有时候开发人员在定义结构体/函数时可能需要记录/传入一些不固定类型的数据, 这种情况可以使用泛型指针 void * 来完成.
先把需要记录/传入的数据的指针的类型转换成 void * 类型, 然后在使用时从 void * 类型转换会原本的指针类型, 最后解引.
#include <stdio.h> void func_generic_ptr(void *data) { printf("%d: ", *(int *)data); } int main(int argc, char **args) { int n = 10; func_generic_ptr((void *)&n); return 0; }
还有分配内存的函数 malloc, 它的返回值类型就是 void *.
之所以可行, 是因为在固定架构下, CPU 寻址大小是固定的, 也就是说, 既然指针变量储存的是内存地址, 那么所有类型的指针变量的大小都是一致的.
而指针变量的类型则是告诉编译器: 指针指向的内存区块有多大. 内存区块的大小只有在解引时才有意义, 因为需要知道应该读多少个字节的连续内存, 而不是把区块以外的数据也读取了.
我们可以把物理内存看作是一个数组, 内存地址就是数组元素的索引, 因此内存地址就是一个整数.
C 语言的标准定义了一种专门储存内存地址的非指针类型 uintptr_t 以及 intptr_t, 不用 int 来储存则是因为 int 的大小不适合用来储存内存地址.
而这两个类型则是专门对此进行调整了的, 在不同平台上能够好好的储存内存地址, 因此可以替代 void * 的使用.
#include <stdio.h> #include <stdint.h> // 这两类型定义在该头中 void func_generic_ptr(uintptr_t data) { printf("%d: ", *(int *)data); } int main(int argc, char **args) { int n = 10; func_generic_ptr((uintptr_t)&n); return 0; }
uintptr_t 和 intptr_t 更多是用来对内存地址做数学运算的.
未定义行为 (undefined behavior, UB)
未定义是指语言规范并未说明该情况该如何处理, 这种情况就是未定义行为.
不同的编译器对未定义行为的处理是不一样的, 因此代码里面不要有这种行为,
比如下面这种,
#include <stdio.h> int main(int argc, char* args[]) { int i = 1; printf("Unpredictable result: %d\n", (++i) + (++i)); return 0; }
GCC 编译得到的程序, 其计算结果是 6; 而 Clang 编译后得到的程序的计算结果是 5.
这是只是其中一种未定义行为, 维基百科上总结其它情况, 有兴趣可以看一下.
函数的参数声明
按照参数个数来分类的话, C 语言的函数声明共有 4 种.
以声明加法函数 add 为例,
带参数类型
int add (int a, int b);
或者
int add (int, int);
禁止调用时被传入参数
int add (void);
这种声明方法实际上是第一种声明的特例, 调用这种函数的时候不能传入任何参数.
不声明任何参数, 但调用时可以传入任意参数
int add ();
这种声明法一般是搭配
extern来用, 链接时引用外部的add函数,而外部的
add函数参数声明可能会有几种情况, 比如int add (int, int)和int add (int, int, int).那么
int add ()这种声明方法就能够很好地兼容这两种情况.C语言的前身是B语言,B语言的函数是没有类型的.C继承了这点, 只是后来的标准添加了类型支持.为了向后兼容已有的旧代码, 编译器就允许这种空参数列表的函数声明. (从这点看,
C语言不折不扣的是一门弱类型语言.)拿
GCC来说, 如果你想编译器严格执行类型检查, 那么在编译时使用 -Wstrict-prototypes 选项提示警告.严格上来说这是
K&R C的语法, 只是对于从ANSI C上手的人(本人就是)而言初看不起眼, 细看吓一跳.同样的惊喜还出现在函数的定义上, 假设
add是一个把两个整数相加再返回整数的函数,在
K&R C里面是这么定义的:int add (a, b) int a; int b; { return a + b; }
自己写新项目的话尽量不要这么写, 毕竟这语法不属于
ANSI C里面, 以后可能要被淘汰.可变参数
C语言本身支持定义参数的数量/类型不固定的函数, 这些函数叫做可变参数函数(varargs functions or variadic functions).但是
C语言本身不给函数提供访问可变参数的机制, 因此这方面工作就要交给库来完成了.GNU libc的stdarg.h就提供这些功能.#include <stdarg.h> int add (int count, ...) { va_list argp; int i = 0; int sum = 0; va_start ( argp, count ); /* Initialize the argument list. */ /* the second of va_start is the name of last argument before arg list. */ for (; i < count; i++ ) sum += va_arg ( argp, int ); /* Get the next argument value. */ va_end ( argp ); /* Clean up. */ return sum; } int main (void) { return add ( 4, 1, 0, 3, 4 ); }
va_start宏初始化参数列表, 该宏的第二个参数是参数列表之前的一个参数, 这里是count;va_arg获取列表里面下一个的参数, 其中还得给出该参数的类型, 该例子里面的函数add的作用是对所有整数进行求和,也就是说所有参数都是
int类型, 所以例子里面的参数类型是int.va_end结束参数列表调用, 该宏的参数得和va_start的第一个参数对应.如你说见,
add需要传入一个count来表示参数列表的参数个数, 这是因为没有官方宏/函数来获得参数列表的长度.不过有人通过宏来 有限 地提供获取参数列表的长度, 比如:
#define VA_NUMS_HELPER(_1, _2, _3, _4, _5, _6, N, ...) N #define VA_NUMS(...) VA_NUMS_HELPER(__VA_ARGS__, 6, 5, 4, 3, 2, 1, 0)
这个自定义的
VA_ARGS可以获取到最大长度为 6 的参数列表的长度.这个
VA_ARGS利用了 "可变参数宏可以获得...部分之前的最后一个参数" 的原理以及通过错位传入参数来获得长度.VA_ARGS(a, b, c) /* 首先展开为 VA_NUMS_HELPER(a, b, c, 6, 5, 4, 3, 2, 1, 0), 通过观察 VA_NUMS_HELPER 的定义可以发现 (2, 1, 0) 这三个参数就属于 ... 部分, 所以 VA_NUMS_HELPER 宏就被展开成这 3 个参数的前一位 3, 这也正是参数列表 (a, b, c) 的长度. */
之所以说是有限, 是因为在
VA_NUMS_HELPER的宏定义的占位符参数(_1, _2, _3, _4, _5, _6) 是固定编码, 并非动态的,你想要测量长度超过 6 的参数列表, 那么就得修改
VA_NUMS_HELPER的定义.因此, 开发人员无法在不改变
VA_NUMS_HELPER定义的情况下获得任意长度的参数列表.那么如何使用这个宏呢? 就以
add为例, 我们定义一个同名宏 (需要注意同名宏要在定义/声明之后):// header.h int add (int count, ...); #define add(...) add(VA_NUMS(__VA_ARGS__), __VA_ARGS__) // in some c source files add(1, 2, 3);
不透明结构体 (Opaque Structures)
不透明结构体就是把结构体的声明和定义分开, 声明放在头文件(.h)里面, 定义则是放在实现的源文件(.c)里面, 以达到结构体定义可以被隐藏的目的.
假设你现在写了一个程序 A, 定义一个 op_node_s 的结构体, 由于这个结构体设计了一些隐私, 并不想在发布程序 A 时把 op_node_s 的定义也发布出去, 只想让用户使用和它相关的函数.
这种情况下就要使用不透明结构体来解决.
具体做法是把 op_node_s 的定义去掉, 并且为 op_node_s 声明一个新类型 op_node_t, 并把函数的声明中的 op_node_s 替换成 op_node_t.
首先 是头文件 op_node.h, 这里面只放声明.
/* op_node.h */ #ifndef __OP_NODE__H #define __OP_NODE__H typedef struct op_node_s op_node_t; int op_node_new(op_node_t **pp_op_node); void op_node_free(op_node_t *p_op_node); void op_node_set_value(op_node_t *p_op_node, int value); #endif
其次 是 op_node.c, 这里面是头文件声明的相关实现, 我们的 op_node_s 的定义就在这里.
/* op_node.c */ #include <stdlib.h> #include "op_node.h" struct op_node_s { int value; }; int op_node_new(op_node_t **pp_op_node) { (*pp_op_node) = (op_node_t *)malloc(sizeof(op_node_t)); if (NULL == *pp_op_node) { return -1; } (*pp_op_node)->value = 0; return 0; } void op_node_free(op_node_t *p_op_node) { free(p_op_node); } void op_node_set_value(op_node_t *p_op_node, int value) { p_op_node->value = value; }
在为不透明结构体提供定义时, 需要注意一点: 不建议使用在定义结构体时引用结构体自己的类型声明(甚至是头文件里面的任何声明).
假设我们要定义的不透明结构体
op_node_s是一个递归结构体, 如下:struct op_node_s { int value; op_node_s *next; };那么不要定义成:
struct op_node_s { int value; op_node_t *next; };这么做的目的是为了不必要的
#include指令.有时候你可能想然
op_node_s的定义在程序A的其它地方被使用, 人们通常会把结构体的定义单独定义在_private.h后缀的文件中,在发布程序的其它地方引入该文件, 换在这里的话, 文件的名字正常来说就是
op_node_private.h;如果把
op_node_s修改成了 "不建议" 的形式, 那么每次引入op_node_private.h时就得同时引入op_node.h, 毕竟op_node_t是声明在op_node.h里面./* op_node_private */ #ifndef __OP_NODE_PRIVATE__H #define __OP_NODE_PRIVATE__H struct op_node_s { int value; }; #endif最后把
op_node.c修改如下:#include <stdlib.h> #include "op_node.h" #include "op_node_private.h" int op_node_new(op_node_t **pp_op_node) { (*pp_op_node) = (op_node_t *)malloc(sizeof(op_node_t)); if (NULL == *pp_op_node) { return -1; } (*pp_op_node)->value = 0; return 0; } void op_node_free(op_node_t *p_op_node) { free(p_op_node); } void op_node_set_value(op_node_t *p_op_node, int value) { p_op_node->value = value; }
最后 在发布阶段时, 你要把 op_node.c 编译成一个链接库 O, 把它和 op_node.h 一起打包发布,
用户只需做两件事情就可以调用你的发布功能了:
- 引入
op_node.h - 运行程序时链接你发布的库
O
/* main.c: test op_node */ #include "op_node.h" int main(int argc, char **argv) { op_node_t *node; op_node_new(&node); op_node_set_value(node, 10); op_node_free(node); return 0; }
这里需要着重对该使用例子进行一下说明, 在定义/声明不透明结构体时, 只能定义/声明不透明结构体的指针,
也就说 op_node_t node 是不行的, 但 op_node_t *node 是可以的,
这是因为此时结构体的实现是被隐藏了的, 而引入的头文件 op_node.h 里面只有结构体的声明,
编译器是无法在结构体定义缺失的情况下为不透明结构体的变量分配空间, 但编译器还是知道指针的大小的,
同时这也禁止在使用中直接进行 malloc(sizeof(op_node_t)) 这样的内存分配操作,
只能在 op_node.c 提供的 op_node_new 函数来完成;
但是直接使用
free(node)操作是没问题的
因为同样的理由, 无法直接通过 node 来操作结构体的成员 value,
编译器会提示 Incomplete definition of type 'struct op_node_s' 错误,
只能通过 op_node.c 里面提供的函数 op_node_set_value 来操作,
所有对于结构体成员的操作都受限于 op_node.c 有没有提供相应的实现,
比如这里因为 op_node.c 没有提供相应函数而无法获取 node 的 value 值.
现实中很多软件都使用了不透明结构体, 让使用者专注于 API 而不是结构体的细节.
其中的一个例子就是 SQLite 3, 它的 sqlite 类型就是一个不透明结构体.
标签联合体 (Tagged Union)
一个联合体是一个可以储存任意类型的内存区域. 比如一个联合体可以储存 int 或 char 类型, 那么这个联合体的大小就是 sizeof(int),
因为需要在保证能够储存 char 的同时保证储存 int 的可能性.
union ExampleUnion { int i; char c }; union ExampleUnion example = { .i=100 }; example.c = 'c';
这个例子里面对 c 成员进行赋值会对 i 成员已存在的数据造成"破坏", 所以, 在同一时间内只能使用一个联合体成员进行数据读写.
相比结构体, 联合体更加节省内存. 其次, 它还有一个妙用.
C 语言的函数无法返回多种可能类型的返回值, 然后有时就是有这种需求.
比如说有一个函数, 接受两个 int 型参数, 进行除法运算并返回结果. 按照结果而言, 分三种可能:
一是两个参数满足整除, 那么结果就是 int;
二是不满足整除, 那么结果就是 float/double;
三是除数是 0, 那么不应该有结果, 或者结果为无限大.
这种时候可以使用标签联合体来解决.
union divResult { int i; /* 第一种情况 */ float f; /* 第二种情况 */ char c; /* 第三种情况, 我们用一个字符来表示计算无结果, 其实可以不需要该成员 */ }; typedef struct { enum { T1, T2, T3 } type; /* T1, T2, T3 分别代表上述三种情况, 这三个就是标签 */ union divResult value; } divResult_t; divResult_t div(int a, int b) { if (b == 0) { return (divResult_t){ .type=T3, .value={ .c='I' } }; } if ((a % b) == 0 ) { return (divResult_t){ .type=T1, .value={ .i=(a / b) } }; } else { return (divResult_t){ .type=T2, .value={ .f=((float)a / b) } }; } } int main() { divResult_t res = div(3, 2); if (T2 == res.type) { printf("float result: %.2f\n", res.value.f); } divResult_t res2 = div(4, 2); if (T1 == res2.type) { printf("integer result: %d\n", res2.value.i); } divResult_t res3 = div(4, 0); if (T3 == res3.type) { printf("Cannot devided by Zero\n"); } }
实际上返回多种可能类型的解决方法还有很多, 比如可以使用结构体来替代联合体(, 相比联合体浪费空间); 还能使用 void * 或者 uintptr 来替代(, 后续根据类型解引).
对比 C++, C 的优点
良好的
ABI兼容性C++有着复杂的名字改编(name-mangling), 而名字改编又没有规范,这导致了不同编译器生成的二进制文件的符号是不确定的, 也就是说不同编译器之间生成的二进制文件无法彼此调用, 这就是所谓
C++的ABI不兼容.我们都知道
C++有命名空间以及函数重载,C++也就是说可以有很多个同名变量, 函数, 而学过汇编的都知道,一个程序里面是不可能有多个同名符号的, 因此根据
C++生成的二进制文件里面, 这些重名的函数都是加了一些前后缀来进行避同的.而
C是没有命名空间和函数重载的, 这个缺点换来了ABI兼容良好的优点.不过
C++提供链接规范(linkage specification)来为不同的语言声明链接协议,比如
C++模块可以为C模块提供避免名字改编的稳定符号, 从而实现C和C++的模块相互调用的, 这就是C/C++混合编程的真相.本人写了一个简单而完整的例子, 可以参考一下(点击下载).
我们把
C++代码导出的C API叫做C Wrapper API或者C bindings, 这个例子就是C++为创建C Wrapper API的基本原理.实际中过程要考虑很多东西, 具体要考虑的事项参考这个 Mixing C and C++ Code in the Same Program,
个人觉得这篇文章关于处理
C++的异常(exceptions)和类(classes)的部分说得不是太好, 所以我又额外提供了另外一个例子: Example of using C++ from C.稳定的标准
两者的语言标准都是有国际组织维护的.
C++比C更新更加频繁, 语言特性逐年增加.这导致了
C++十分臃肿, 真要掌握起来学习成本极高.而
C就没那么多特性, 概括起来就只有: 基本数据类型, 变量, 控制流语句, 函数, 指针, 宏.前面 4 个东西基本上只要是门编程语言都有的了, 而指针和宏则是大部分语言所没有的.
早期在
IT行业打下了基础, 现在也不需要大改标准, 因此它可以说是语法简单, 功能强大, 学了就终身受用.至于深受人们追捧的面向对象编程(
OOP),C语言确实不支持, 但实际上也是可以在C里面使用上的.实际上
OOP原本不是什么高深的东西, 下面的内容是OOP提出者Alan Kay对OOP的定义:(I'm not against types, but I don't know of any type systems that
aren't a complete pain, so I still like dynamic typing.)
OOP to me means only messaging, local retention and protection and
hiding of state-process, and extreme late-binding of all things. It
can be done in Smalltalk and in LISP. There are possibly other
systems in which this is possible, but I'm not aware of them.
当然了, 现在很多语言的
OOP比起最初的定义复杂太多了.而我们也不需要手动实现
OOP, 已经有人现成方案了(参考Glib的GObject子模块, 有兴趣的可以看一下这篇文章).如果要自己实现, 那么建议阅读一下 "21st Century C, 2nd Edition" 的第十一章.
一些编码习惯和理由
为何人们喜欢把
if相等判断的常量放在双等号前面?if (0 == res) { // ... }
这是因为
C/C++语言是可以在if语句里面对变量进行赋值的, 程序员可能会因为粗心写出如下代码:if (res = 0) { // 原本想写 res == 0 // ... }
而把常量放在前面则可以被编译器提示错误.
如何禁止编译器提示
"unused parameter"警告?方法很多, 但有一个很奇怪的方法可以适用于任何编译器, 比如,
void f(int x) { return; (void)x; }
只要在函数里面使用
(void)param这样就可以禁止这类警告了, 这个例子是在return之后使用,这个其实无所谓, 喜欢的话也可以放在
return之前. 另外可以查看这个链接:https://stackoverflow.com/questions/3599160/how-can-i-suppress-unused-parameter-warnings-in-c
C 语言应用教材
如果想学习 C 标准库的使用, 或者说 Linux 系统编程, 那么 The Linux Programming Interface 这本书就是必看的.
这本书的内容可以说是开发人员的必备基础之一, 同时也可以说是 C 语言练习册.
关于调试
在调试方面来说, 个人认为编译型语言要比解释型语言复杂.
编译型语言的调试就像是别人把一篇文章翻译成另外一种语言, 并要求你看着译本把原文中错误找出来;
解释型语言就是直接把原文给你并要求你把错误找出来.
作为编译型语言的 C 来说调试就是一件麻烦事, 不过掌握之后可以让你在排查程序错误中大显神通, 即便程序不是你写的.
如果你是一个 Linux 用户, 又会汇编和 C, 那么我推荐一本关于调试的书 "Debug Hacks".
这本书的内容可以分为程序调试和 Linux 内核调试两大块, 可以根据自身需求去阅读.
GCC flags 的最佳实践
禁止单精度/双精度/整型之间的隐藏式装换
在 C 语言里面, 可以对数据进行隐式转换(implicit conversion). 比如:
int cloest_t = 3.14;
浮点数字面值(例如这里的 3.14)是双精度浮点数, 这个赋值会把双精度浮点数转换成整型, 也就是 cloest_t 的值是 3.
在一些数学计算中, 3 和 3.14 可能会让计算产生截然不同的结果, 这可能是开发人员的粗心导致的,
可以设置编译选现让编译器提醒潜在问题: GCC 的 -Wfloat-conversion.
该选项会提醒开发人员代码里面进行了 float 到 int 的隐式转换:
警告原文:
warning: conversion from ‘float’ to ‘int’ may change value [-Wfloat-conversio]
另外, 没有对宏的转换进行警告, 比如:
#define INF 3.14 int cloest_t = INF;这点需要自己注意, 个人认为这可能是 BUG, 可能在之后的
GCC版本里面被修正.
倘若真的想要进行转换, 那么可以使用显式转换:
int cloest_t = (int)3.14;
这样, 编译器就不会有警告了.
最后就是单精度浮点和双精度浮点之间的转换了.
这个是 GCC 手册里面的一个例子, 函数里面让双精度浮点和单精度浮点进行相乘.
float area(float radius) { return 3.14159 * radius * radius; }
针对这个运算, 编译器会先让单精度浮点升格(promotion)为双精度浮点再进行运算, 最后把双精度浮点的结果降格(demotion)为单精度浮点进行返回.
在机器层面上, 双精度浮点数的计算需要更多的代价.
这段代码有两个解决方法:
针对这类问题, 可以使用 GCC 的 -Wdouble-promotion 选项来警告该类问题.
事实上, -Wfloat-conversion 也会对这个问题进行警告.
总的来说, 为了禁止双精度浮点/单精度浮点/整型之间的隐式转换, 我们应该使用 -Wdouble-promotion -Wfloat-conversion,
或者就单独使用 -Wfloat-conversion, 而这两个选项是 不会 在 -Wall 中被启用的.